전체 게시글 (23)
[Blocking vs Non-Blocking] 왜 헷갈릴 수밖에 없는가 - 애매성에 대한 언어학적 해설
서론 Blocking 과 NonBlocking의 개념에 대해 익히 공부하셨을 겁니다. 보통 작업이 완료될 때까지 제어권을 반환하는가로 구분됩니다. 호출한 작업이 끝날 때까지 호출한 쓰레드는 멈추게 된다고도 해설하죠. 다만 아래 함수는 Blocking Function 일까요? 함수는 작업이 완료될 때 까지 호출자에게 제어권을 반환하지 않습니다. 이 경우 블로킹 함수라 정의할 수 있죠. 다만, 함수는 작업이 완료될 때 까지 스레드의 제어 아래에 있습니다. 이 경우 스레드는 단순히 Busy하게 작업을 진행할 뿐, OS에게 제어권을
![[Blocking vs Non-Blocking] 왜 헷갈릴 수밖에 없는가 - 애매성에 대한 언어학적 해설](https://d2r0pavv0lsiqc.cloudfront.net/posts/images/d562c662-0f69-45ad-bf9b-58de3e515ccd.webp)
Servlet Container 직접 만들기 - Servlet API 구현 및 런타임 제공
Java 애플리케이션에서 개발자가 저수준의 소켓 제어 및 프로토콜 명세에 맞도록 데이터 규격화를 직접 하지 않도록 하기 위해 Java EE에서 Servlet API라는 표준화된 인터페이스를 제공합니다. 또한 Servlet API의 구현체를 정의하고, 이를 기반으로 실제 통신을 처리할 수 있도록 하는 런타임을 서블릿 컨테이너라고 정의합니다. Tomcat, Jetty와 같은 다양한 상용 구현체가 존재합니다. 서블릿 컨테이너의 역할 및 기능을 직접 눈으로 보고 코드로 녹여내보기 위해서, Servlet API를 직접 구현하고, 이를 실행
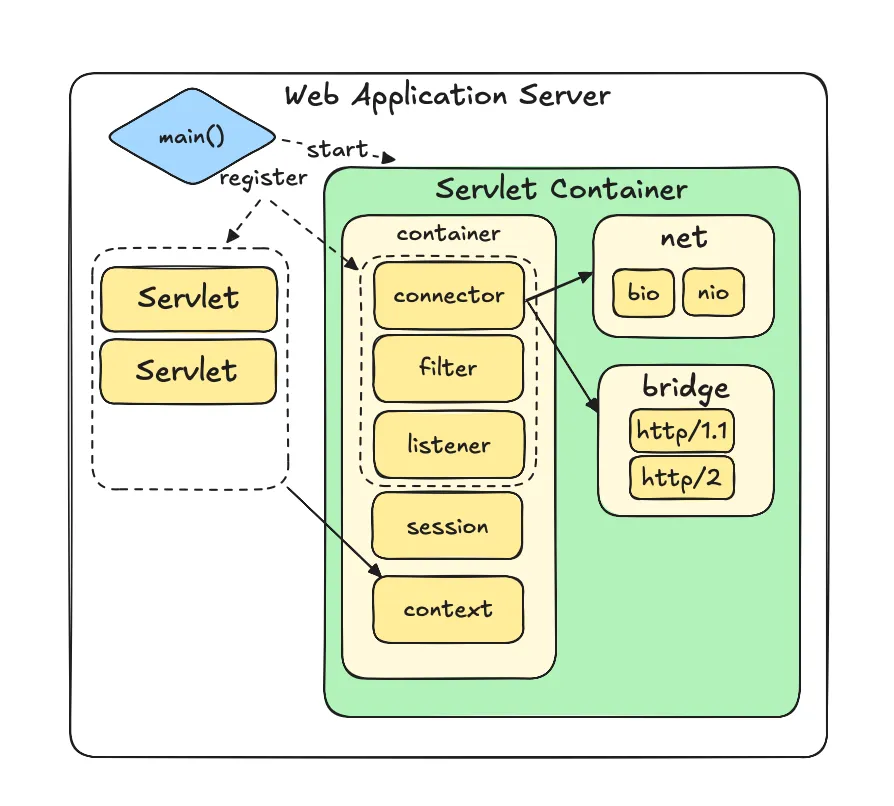
Java TCP 소켓 HTTP 서버 구현, 서블릿(Servlet) API의 등장과 개념
시리즈의 지난 글에서 의존성 없이 자바 순수 코드로 TCP 소켓 서버를 만들어보았습니다. 소켓 통신 서버를 구현하며 응용 프로그램에서는 유의미한 요청/응답 체계를 갖추려면 TCP 프로토콜보다 상위의 규격화된 프로토콜이 필요하다는 것을 느꼈습니다. 앞으로 HTTP에 대해 아래와 같이 다루어보겠습니다. 순수 JDK 코드로만 소켓을 활용해 HTTP 서버를 대강 구현해보기 HTTP 서버에게 있어 표준화된 명세의 필요성을 확인하기 Servlet API가 무엇인 지 알아보기 직접 Servlet API를 구현하기 직접 만든 서블릿
Java TCP Socket 구현 - 세그먼트, 송수신 버퍼, 바이트 스트림과 소켓 핸들링
시리즈의 지난 글에서 Socket API의 개념 및 명세, Java 언어에서 어떻게 객체화가 되었는 지, 실제 JDK 코드 내에서 어떻게 OS 별 시스템 콜을 호출하는 지 까지 직접 소스코드를 분석해 보았습니다. 이번 글을 통해 Socket API를 직접 사용하고, Java Application에서 TCP 통신을 구현해보도록 하겠습니다. 소켓 자체에 대한 개념은 다루지 않으니 지난 글 먼저 보고 오시길 바랍니다. 포스팅에 활용된 전체 소스코드는 아래 링크의 1번 모듈에서 보실 수 있습니다. TCP Segment와 소켓 버퍼
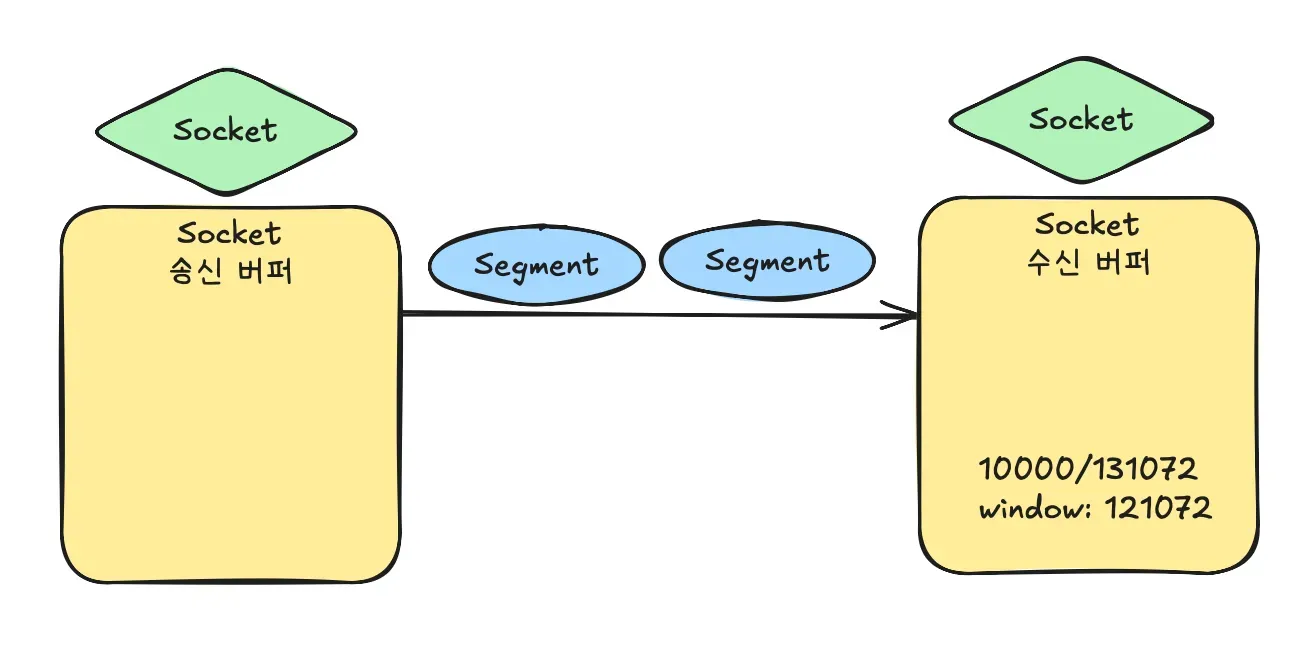
커널부터 Socket.java까지 소켓 추상화 스택 분석
서버 개발자의 본질은 네트워크를 통해 클라이언트의 요청을 수신하고 이에 대한 응답을 제공하는 애플리케이션을 만드는 데 있습니다. 오늘날에는 수많은 추상화 덕분에 개발자가 네트워크 설정을 직접 다루지 않아도, 단순히 Controller라는 개념을 사용해 직관적인 코드만으로 HTTP 서버를 띄울 수 있게 되었습니다. 그러나 추상화는 본질적으로 동작을 은닉하고 이를 고수준의 언어로 포장합니다. 이 과정이 겹겹이 쌓이다 보니 서버, 통신, HTTP, 서블릿, 톰캣, 스프링, 스프링부트 등을 설명하는 글들은 오히려 불필요한 첨언과 혼란스러
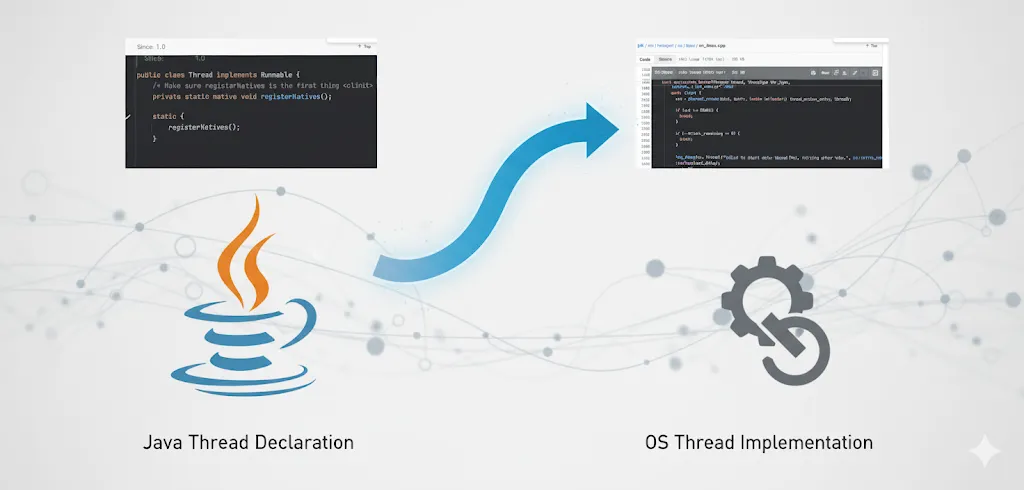
Java의 new Thread()는 어떻게 OS 커널 스레드가 될까?
Java에서 new Thread() 를 호출하면 OS의 커널레벨 스레드와 1대1로 매핑된다고 흔히들 공부하실 겁니다. 다만 이 인스턴스가 OS에서 다루는 스레드까지 도대체 어떤 과정을 통해서 매핑되는 지는 와닿지 않으실겁니다. 사진 출처: 우아한 기술 블로그 개발자 이전에 공학도로서 한번 top-down으로 파고들며 분석해보겠습니다. OS부터 올라오기 보단 친숙한 Java 애플리케이션 레벨 부터 시스템콜을 호출 하는 부분까지 실제 동작 과정을 코드를 타고가며 관측해보겠습니다. 코드 분석 Java 표준 라이브러리 - Thr
결제 도메인의 재시도 상황 및 전략, 멱등성 연계
결제 과정은 금전과 관련된 일이기 때문에 반드시 한번 이상의 처리를 보장해야합니다. 이를 보장하려면 필연적으로 재시도가 생겨납니다.  네트워크 끊김 등 모든 상황에서도 한번 이상 올바르게 처리되도록 하기 위해서는 트랜잭션으로 보장받지 못하는 모든 연결부에서 발생하는 케이스에서 실패 시 재시도가 되어야 하기 때문입니다. 따라서 똑같은 로직이 여러번 발생하는 경우 생기는 문제를 막기 위해 멱등성을 보장했습니다. 시리즈의 전 포스트를 참고해주세요. 이번 글에선 결제 도메인에서 재시도 처리를 해야하는 케이스들을 살펴보고,

protobuf 관리 전략 – Submodule, Buf, Schema Registry
IDL로 protobuf를 도입했을 때 필연적으로 따라오는 것은 protobuf에 대한 관리 문제입니다. IDL은 통신에서 사용되는 공유 계약으로 이용되어 서비스가 동일한 IDL 스펙을 반드시 따라야하게 만듭니다. 특히 protobuf 같은 경우엔 각 값의 key 값이 따로 존재하지 않고 field number만 이진화되어 전송되기 때문에, 해석하는 측에서 직렬/역직렬화 과정에서 이를 올바르게 해석하려면 양쪽 서비스가 동일한 proto 정의를 공유하고 있어야 합니다. 따라 protobuf를 올바르게 사용하고 관리하기 위해서는 스

gRPC vs HTTP/REST - 실제 서비스 환경에서의 부하 테스트로 살펴본 성능과 오버헤드
마이크로서비스 아키텍처가 자리 잡으면서 서버 간 통신 방식으로 gRPC가 주목받고 있습니다. 많은 아티클에서 “gRPC는 HTTP/1.1 기반 API보다 빠르다”라는 이야기를 접해보셨을 겁니다. 하지만 실제로 얼마나 빠른지, 어떤 상황에서 빠른지, 그리고 기존 벤치마크 결과가 얼마나 신뢰할 만한지는 직접 실험해보지 않으면 체감하기 어렵습니다. 이번 글에서는 클라우드 환경에 배포된 DB I/O, Kafka 등이 연결된 실제 애플리케이션을 대상으로 부하 테스트를 진행했습니다. 단순히 프로토콜 차원뿐만 아니라, 애플리케이션 내부의 풀
[Spring] 카프카 의존성 - Spring Cloud Stream vs Spring Kafka
스프링에서 카프카 Producer과 Consumer를 사용하기 위해서는 대게 2가지 방법이 있습니다. 바로 Spring Cloud Stream 과 Spring Kafka입니다. 두 기술은 서로 철학과 장단이 다른데, 이름에서 볼 수 있듯 Spring Cloud Stream은 추상화 레벨이 높고, Spring Kafka는 Kafka라는 이름이 직접 들어가는 만큼 더 세밀한 카프카 지향적인 제어가 가능합니다. 이번엔 두 기술을 비교해보며 각각의 철학 및 사용법을 확인해보고 장단점을 알아보겠습니다. 스프링 클라우드 스트림 (Spri
![[Spring] 카프카 의존성 - Spring Cloud Stream vs Spring Kafka](https://d2r0pavv0lsiqc.cloudfront.net/posts/images/10600609-c645-4892-8c2f-6cb15c0f1ac4.webp)