![[Spring] 카프카 의존성 - Spring Cloud Stream vs Spring Kafka](https://d2r0pavv0lsiqc.cloudfront.net/posts/images/10600609-c645-4892-8c2f-6cb15c0f1ac4.webp)
스프링에서 카프카 Producer과 Consumer를 사용하기 위해서는 대게 2가지 방법이 있습니다. 바로 Spring Cloud Stream 과 Spring Kafka입니다.
두 기술은 서로 철학과 장단이 다른데, 이름에서 볼 수 있듯 Spring Cloud Stream은 추상화 레벨이 높고, Spring Kafka는 Kafka라는 이름이 직접 들어가는 만큼 더 세밀한 카프카 지향적인 제어가 가능합니다.
이번엔 두 기술을 비교해보며 각각의 철학 및 사용법을 확인해보고 장단점을 알아보겠습니다.
스프링 클라우드 스트림 (Spring Cloud Stream)
개념 및 철학
스프링 클라우드 스트림은 확장성이 뛰어난 이벤트 기반 마이크로서비스를 구축하기 위한 프레임워크입니다. Kafka 뿐만 아니라 RabbitMQ, AWS SNS 등등 여러 메시지 큐와의 통합을 지원합니다.
이 기술은 구체적 기술 명세가 은닉되고 Binder라는 추상화계층을 두어 이를 활용합니다.
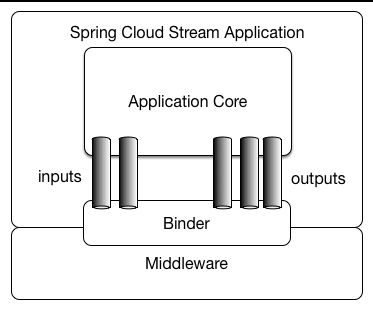
그림의 MiddleWare에 해당하는 부분이 Kafka 등의 메시지 큐 구현에 해당합니다. 따라서 실제 서비스 코드에는 카프카 등의 개념 자체가 등장하지 않죠. Kafka의 파티션, Consumer Group 같은 저수준 브로커 세부 사항은 직접 다루지 않아도 됩니다.
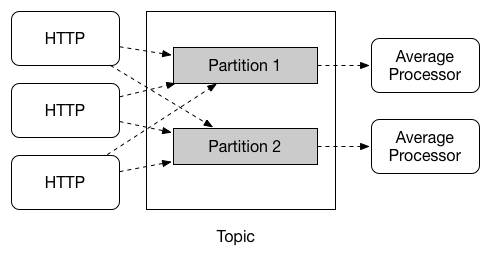
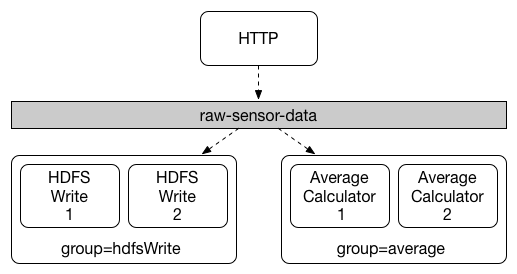
Binder 측에서 Consumer Group, 파티션 수, Offset 관리 등을 처리해 줍니다. 이런 고수준의 추상화임에도 세밀한 제어가 가능한 이유는 바인더 쪽에 kafka라는 기술 명세에 대한 연결을 어떻게 처리할 것인지를 application.yml에서 상세하게 설정 가능하기 때문입니다.
어떻게 보면, Kafka 같은 구체적 기술 명세에 대한 엔지니어링을 application.yml 에 다 집어넣어서 응집도 높게 처리한다고 볼 수 있습니다.
반대로 말하면, 설정 파일로 엔지니어링을 해야 합니다. 호불호가 갈리는 포인트입니다.
애플리케이션에서의 코드
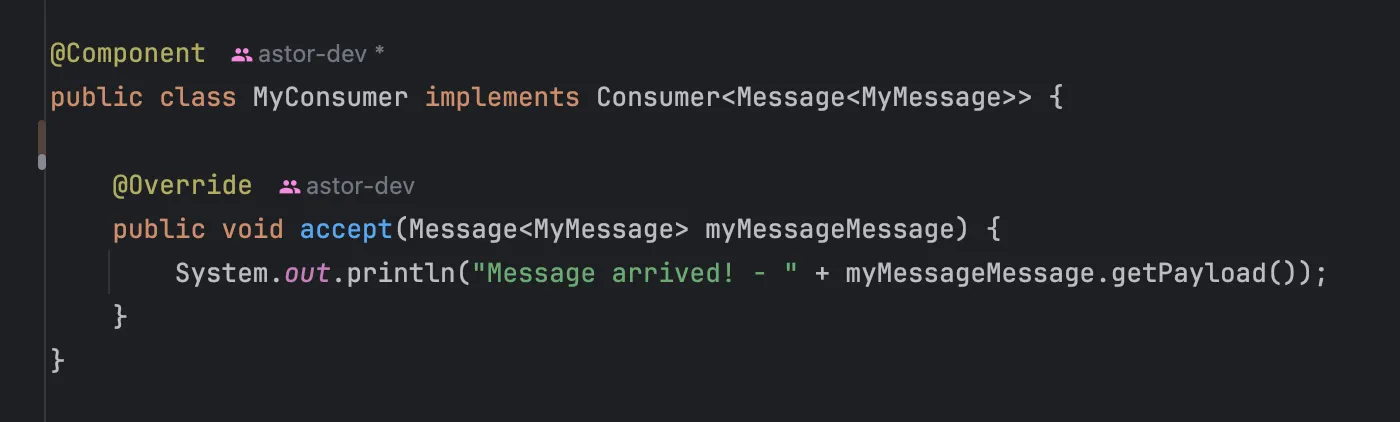
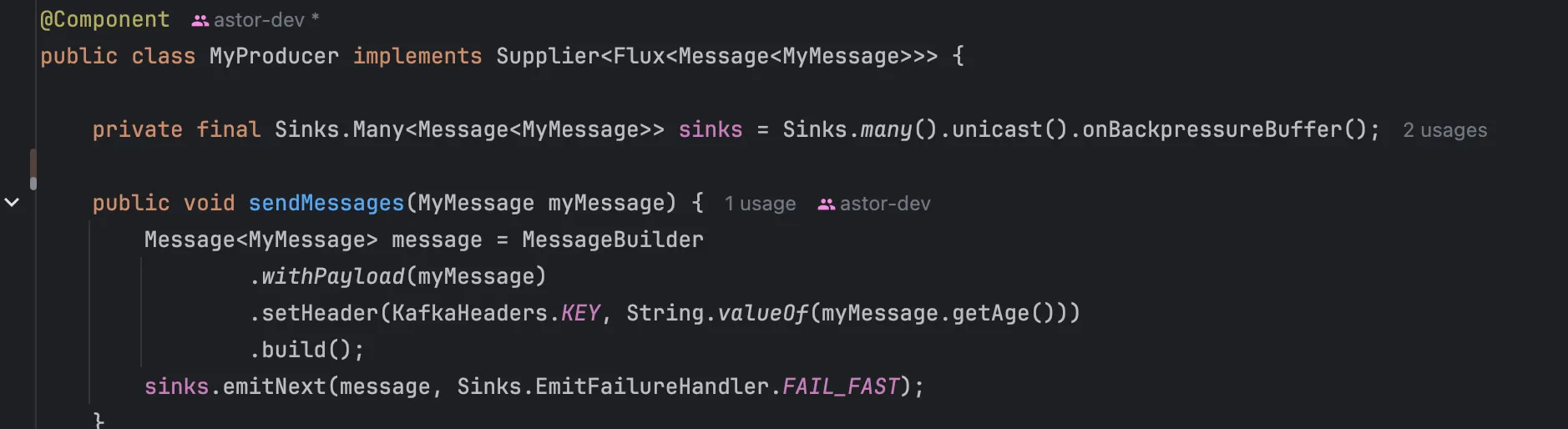
이런 식으로 컨슈머나 프로듀서를 등록합니다.
또 신기한 점은 컨슈머 및 프로듀서 측 코드만 봤을 때는 별도의 연결 관련 코드가 없습니다. 이 Bean이 어떤 토픽을 컨슈밍/프로듀싱하는 지, 어떤 컨슈머 그룹인 지 등에 대한 정보를 확인할 수 없죠.
spring:
cloud:
function:
definition: myProducer;myConsumer
stream:
function:
bindings:
myProducer-out-0: producer-test
myConsumer-in-0: consumer-test
kafka:
binder:
brokers: localhost:9092, localhost:9093, localhost:9094
auto-create-topics: false
required-acks: 0
configuration:
key.serializer: org.apache.kafka.common.serialization.StringSerializer
bindings:
consumer-test:
consumer:
start-offset: latest
bindings:
producer-test:
destination: my-json-topic
content-type: application/json
consumer-test:
destination: my-json-topic
group: test-consumer-group
consumer:
concurrency: 1
application.yml 설정 파일 예시입니다. topic이라는 이름 대신 destination 을 쓰는 등의 모습에서 추상화된 개념을 활용함을 알 수 있죠. definition: myProducer;myConsumer 이런 식으로 프로듀서 & 컨슈머 Class를 설정할 수 있습니다.
spring.cloud.bindings 쪽에서 지정해놓은 consumer-test 등에 대한 상세 명세를 spring.cloud.stream.kafka.bindings 에서 kafka-specific 하게 처리할 수 있습니다.
정리
메시지 큐에 대한 고수준의 추상화를 통해서 기술 의존적이지 않게 개발할 수 있다는 장점이 있습니다. 다만, 특정 기술에 대한 세부적인 엔지니어링을 설정 파일에서 모두 해야 한다는 단점이 있습니다.
메시지 큐가 구현해야할 기능과 명세가 SQL 처럼 합의가 되었더라면 JPA 처럼 활용할 수 있겠지만, 아직은 메시지 큐 별로 제공하는 기능이 서로 다르고 복합적이여서 엔지니어링이 필연적입니다. 따라 조금은 불쾌한 개발 경험이 있을 수 있습니다.
Spring Cloud Stream 도입하기 | 카카오페이
카카오페이에서 활용 중인 기술 스택입니다.
처음부터 다 분리하고 규격화하면서 개발하는 건 너무 힘든 일입니다. 개발하면서 공통 부분과 분리할 부분을 잘 찾은 다음에 분리해도 늦지 않고, 언제든 되돌아갈 준비가 되어 있는 게 좋습니다. Spring Cloud Stream은 그런 관점에서 좋은 대안이 될 수 있습니다. 쉽게 분리 및 결합이 가능하고 제거하기도 편합니다.
spring-kafka는 low level로 개발하는 거라서 코딩 스타일 강제가 불가능합니다. 데이터 흐름을 코드 베이스로 파악해야 하는 어려움이 있습니다. 또한 잘못 코딩하게 되면 결합도가 높아집니다. Spring Cloud Stream은 데이터 흐름 제어나 코딩 스타일을 어느 정도 규격화 하는 것이 가능하고 코드 결합도도 낮출 수 있습니다
카카오페이에서 해당 기술 스택을 선택한 이유에 대해 조금 발췌해봤습니다. 어느정도 규모가 있는 서비스에서 개발자들의 코딩 스타일을 강제하여 서비스 개발에서 개발자의 엔지니어링 미스로 생기는 잘못된 설계를 통제할 수 있습니다.
마찬가지로 규모가 작은 서비스에서 Kafka를 사용하고는 싶지만, 인프라적 / 비즈니스적 여건이 안되거나 오버엔지니어링으로 판단 될 때, 확장성을 도모하며 선택할 수 있습니다.
스프링 카프카 (Spring Kafka)
개념 및 철학
스프링 카프카는 Spring의 핵심 개념을 적용하여 Kafka를 엔지니어링 할 수 있게 도와줍니다. application.yml에서 KafkaProperties를 설정하고, ProducerFactory 나 ConsumerFactory를 통해 원하는 설정의 프로듀서나 컨슈머를 만들 수 있습니다.
DI를 통해 KafkaTemplate으로 Producer API를 제어할 수 있습니다.
@KafkaListener 어노테이션으로 컨슈머에 대한 설정을 MVC에서 controller 정의 하듯 간편하게 할 수 있습니다.
애플리케이션에서의 코드
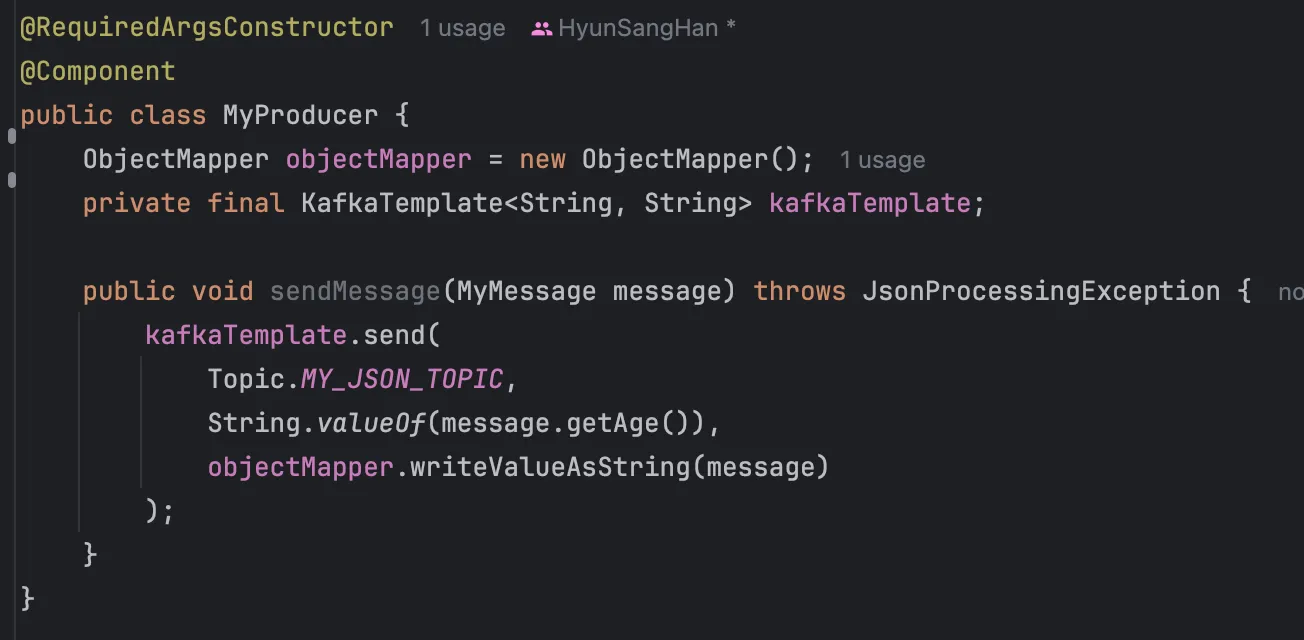 프로듀서 측 코드입니다. 메시지를 어떤 토픽에 어떻게 보낼 것인 지를 세밀하게 제어 가능합니다. 코드에 Kafka나 Topic 같은 개념이 투명하게 드러납니다.
프로듀서 측 코드입니다. 메시지를 어떤 토픽에 어떻게 보낼 것인 지를 세밀하게 제어 가능합니다. 코드에 Kafka나 Topic 같은 개념이 투명하게 드러납니다.
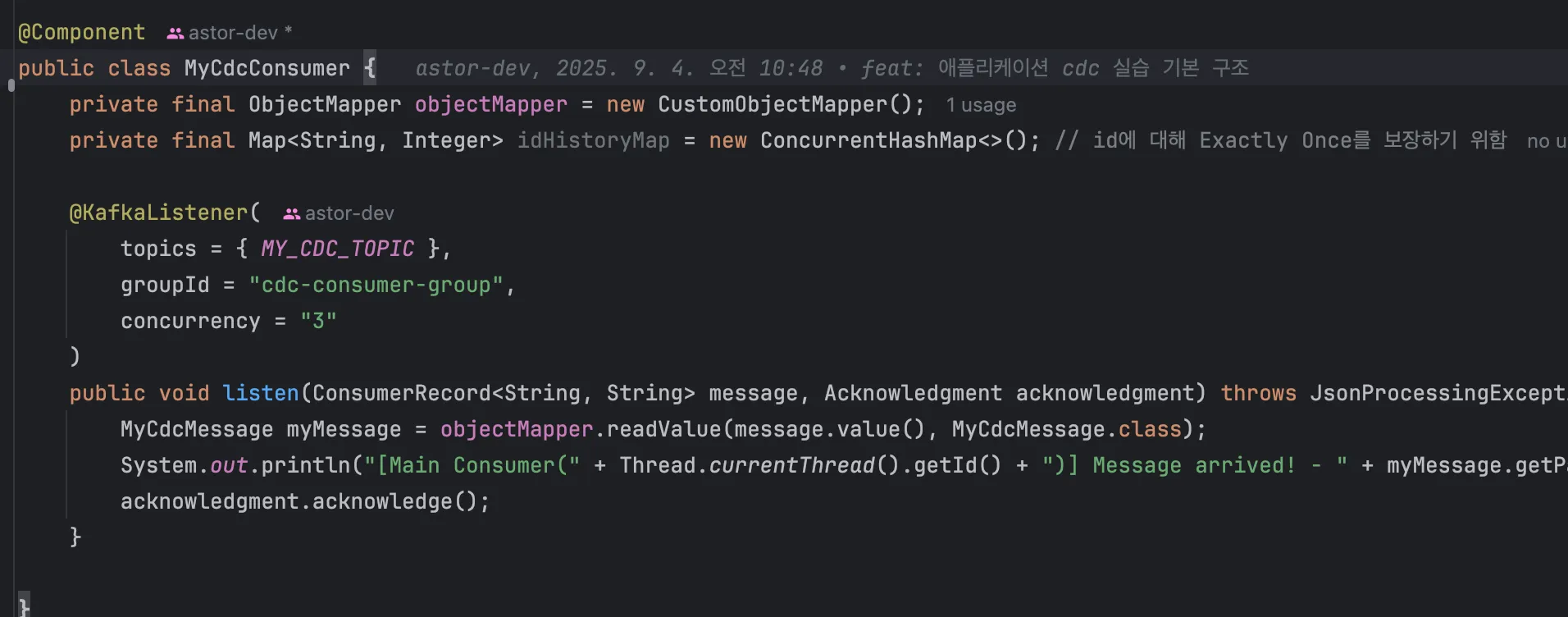
컨슈머 측 코드입니다. 컨슈머 그룹이나 토픽, concurrency 같은 걸 개별 컨슈머 측에서도 제어할 수 있습니다. acknowledgment.acknowledge(); 을 통해 수동 커밋도 제어할 수 있습니다.
Spring MVC와 굉장히 유사하죠? @KafkaListener 어노테이션이 달려 있는 메서드에 마치 MVC에서 HttpServletRequest 받는 것 처럼 상위 어뎁터가 메시지나 ack 객체를 담아 메서드를 호출해줍니다. 이를 통해 컨슈머측 정밀 제어할 수 있습니다.
spring:
kafka:
bootstrap-servers: localhost:9092,localhost:9093,localhost:9094
consumer:
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
acks: -1application.yml 쪽입니다. 이걸로 제어할 수 있긴 하지만 SpringKafka쪽에선 코드레벨에서 설정을 제어하는 걸 선호해서 그리 설정이 들어가지 않습니다. 보통 공통 설정을 처리합니다.

보통 이걸 받아서 팩토리 단에서 일부는 공용 설정으로, 일부는 더 구체적인 설정을 추가하여 처리합니다.
@Bean
@Qualifier("batchConsumerFactory")
public ConsumerFactory<String, Object> batchConsumerFactory(KafkaProperties kafkaProperties) {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaProperties.getBootstrapServers());
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, kafkaProperties.getConsumer().getKeyDeserializer());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, kafkaProperties.getConsumer().getValueDeserializer());
props.put(ConsumerConfig.ALLOW_AUTO_CREATE_TOPICS_CONFIG, "false");
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, ConsumerConfig.DEFAULT_MAX_POLL_RECORDS);
return new DefaultKafkaConsumerFactory<>(props);
}이런 식으로 기본 설정에 커스텀하여 배치 컨슈머 팩토리를 만들 수 있습니다.
@Bean
@Primary
public ConcurrentKafkaListenerContainerFactory<String, Object> kafkaListenerContainerFactory(
ConsumerFactory<String, Object> consumerFactory,
KafkaTemplate<String, Object> kafkaTemplate
) {
ConcurrentKafkaListenerContainerFactory<String, Object> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory);
factory.setCommonErrorHandler(new DefaultErrorHandler(new DeadLetterPublishingRecoverer(kafkaTemplate), generateBackOff()));
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL);
return factory;
}이런 식으로 컨슈머 팩토리에 AckMode(수동 커밋이나 여러 자동 커밋 방식 중 설정)나 예외 처리, Retry 설정 등을 더하여 컨슈머측에서 쓰던 KafkaListener용 팩토리를 설정할 수 있습니다.
@KafkaListener(
topics = { MY_JSON_TOPIC },
groupId = "batch-test-consumer-group",
containerFactory = "batchKafkaListenerContainerFactory",
concurrency = "1"
)이런 식으로 여러 컨테이너 팩토리가 있으면 bean을 골라 쓸수도 있습니다.
정리
코드쪽만 잠깐 보셔도 아시다시피 스프링 클라우드 스트림보다는 훨씬 운용 난이도 및 자유도가 높습니다. Kafka에 대한 이해도가 꽤나 높은 조직이고, 서비스 아키텍처가 잘 모듈화되어 카프카와 관한 로직을 격벽을 잘 쳐서 결합도 낮게 관리할 수 있다면 좋은 선택일 수 있습니다.
다만 카프카 데이터가 어떻게 흘러가는 지 보려면 코드레벨에서의 탐색이 필요합니다. 응집도 높은 모듈을 구현해서 쓴다면 큰 문제가 없겠지만, 토픽이나 설정, 프로듀서, 리스너가 여러 곳에 기준없이 산재된다면 코드가 굉장히 더러워질 수 있습니다.
비교 분석
| 항목 | Spring Cloud Stream | Spring Kafka |
|---|---|---|
| 철학 | 고수준 추상화, 다양한 메시징 시스템 지원 | Kafka 중심 저수준 제어 |
| 코드 특징 | 추상화 API 사용, 브로커 구현 노출 없음 | KafkaTemplate/Listener로 직접 제어, 세밀 설정 가능 |
| 설정 위치 | application.yml 중심 | 코드 중심, 일부 공통 설정만 yml |
| 세밀 제어 | Binder 통해 가능, 설정 의존 | 코드에서 직접 제어 가능 (Ack, Retry 등) |
| 장점 | 기술 의존 낮음, 코드 결합도 낮음, 규격화 가능 | Kafka 기능 완전 제어, 흐름 코드 기반 확인 가능 |
| 단점 | 설정 많으면 복잡 | 코드 산재 시 복잡, Kafka 이해 필요 |
| 적합 상황 | 개발 스타일 통제, 확장성 필요 | Kafka 전문 지식 있는 팀, 모듈화 구조 |
둘의 특성을 표로 정리해봤습니다. 사실 철학과 Spec이 차이나긴 하지만 개념적으로는 메시지 큐 및 카프카를 기저에 두고 있기 때문에 익숙해지면 어느 것이든 좋은 선택일 수 있습니다.
조직 및 프로젝트의 성향에 맞춰 잘 선택하시면 될 것 같습니다.
출처
https://docs.spring.io/spring-kafka/reference/
https://docs.spring.io/spring-cloud-stream/reference/
https://github.com/HyunSangHan/fastcampus-kafka-message-queue