지난 글에선 카프카 프로듀서 측 주요 개념과 발생할 수 있는 시나리오 및 대응법들을 살펴봤습니다. 사실 프로듀서 측은 세팅만 잘 해두면 큰 문제가 생기지는 않습니다. 데이터의 영속화와 메시지 발행간의 무결성만 잘 지킨다면 외에는 크게 신경 쓸 부분이 없기 때문이죠.
다만 컨슈머 측엔 토픽을 다루는 서비스 로직이 들어가다 보니 발생할 수 있는 상황의 복잡도가 굉장히 높습니다. 이번 글에선 컨슈머 측에서 여러 상황을 컨트롤하기 위해 필요한 개념과 방법들에 대해 알아보겠습니다.
오프셋 커밋 전략
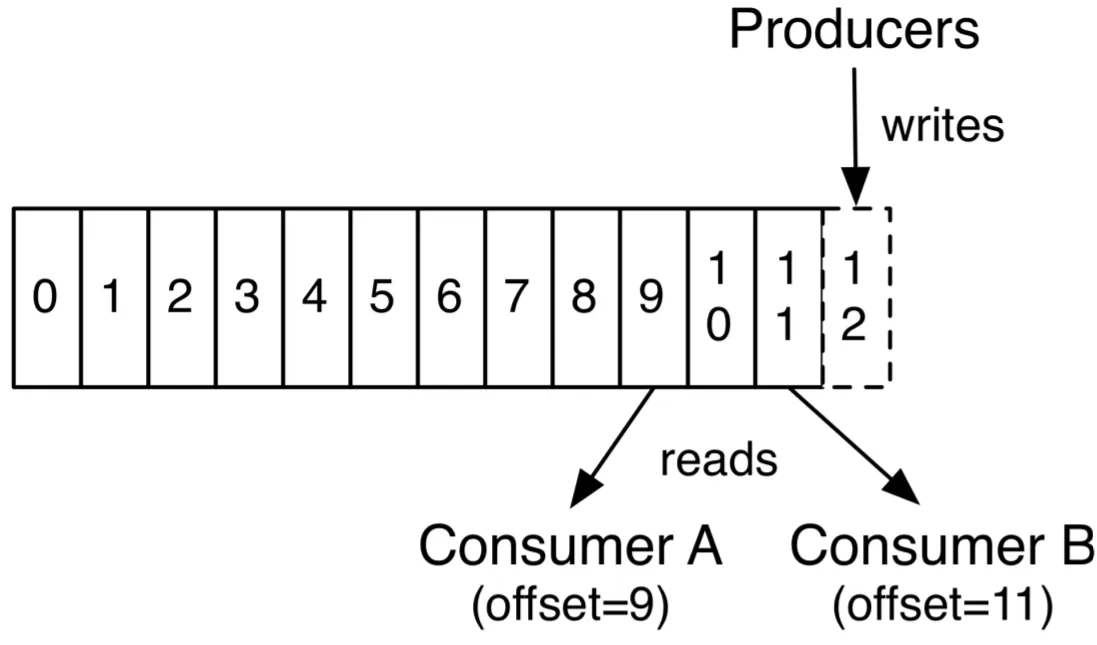
오프셋은 파티션 내에서 각 메시지가 갖는 유일하고 순차적인 식별 번호입니다. 컨슈머가 메시지를 성공적으로 처리하고 나면, 브로커에게 자신이 다음으로 읽어야 할 메시지의 위치, 즉 오프셋을 커밋합니다. 덕분에 컨슈머에 장애가 생기거나 리밸런싱이 일어나도 중단된 지점부터 메시지 처리를 지속할 수 있습니다.
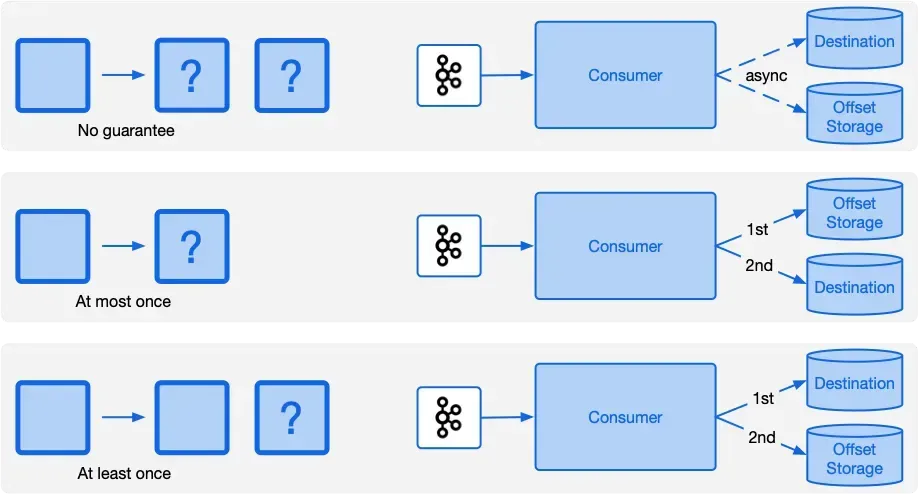
컨슈머는 오프셋을 자동 커밋과 수동 커밋 방식 중 하나로 처리할 수 있습니다. 자동 커밋은 특정한 기준(일정 주기, 일정 개수, 레코드 처리 후 등등)에 도달할 때 마다 오프셋을 커밋하는 방식이고, 수동 커밋은 개발자가 코드 내에서 명시적으로 커밋 시점을 제어하는 방식입니다. 결론부터 말씀 드리자면, 대부분의 경우 수동 커밋이 유리합니다.
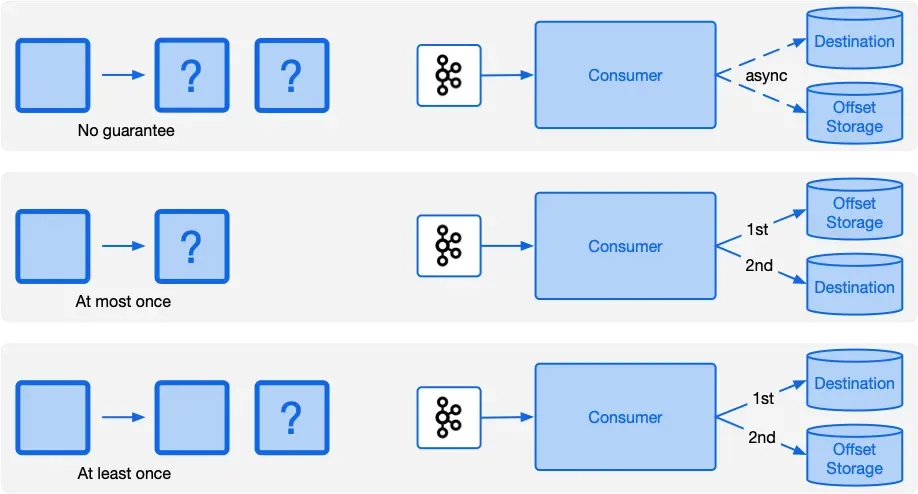
오프셋 커밋 전략은 처리 방법론에 해당하는 자동 커밋 vs 수동 커밋 이전에, at-most-once를 보장하느냐, at-least-once를 보장하느냐로도 나눌 수 있습니다.
이에 따라 데이터가 유실될 수도, 중복 처리될 수도 있습니다. 시나리오를 한번 알아보겠습니다.
at-most-once: 데이터 유실 시나리오
만약 컨슈머가 데이터에 대한 로직 처리 시점 이전에 커밋을 해버리면, 메시지는 최대 한번(at-most-once) 처리된다고 의미할 수 있습니다. 이 경우 로직 도중 서버가 내려가는 등의 이슈가 생길 시 처리 중이던 데이터는 이미 처리된 것으로 커밋된 상태라 데이터 유실이 생길 수 있습니다.
대부분의 주기별, 개수별 등 일부 자동 커밋 상황에서 생길 수 있습니다. 유실은 중복보다도 최악의 상황이기에 지양하는 편이 좋습니다.
at-least-once: 데이터 중복 시나리오
만약 컨슈머가 데이터를에 대한 로직 처리 시점 이후에 오프셋 커밋을 한다면, 메시지는 최소 한번(at-least-once) 처리된다고 의미할 수 있습니다. 이 경우 로직 처리를 완료한 뒤, 오프셋 커밋을 못한 채 컨슈머측 장애가 생겨 재시도하게 된다면 데이터 중복 처리가 생길 수 있습니다.
보통은 이 방식을 선호하고, 수동 커밋으로 로직이 끝난 직후 오프셋 커밋을 하며 중복 처리에 대해서는 애플리케이션 로직 단에서 멱등성을 보장하는 식으로 해결합니다. 멱등성이란 여러번 작업해도 동일한 결과를 불러오는 특성을 뜻하며, 주로 upsert를 통해 여러번 업데이트 되어도 동일한 결과가 나오게 하거나, 이벤트에 고유한 Idempotency-Key를 담아서 Redis 등과 연계에 중복 처리 유무를 확인하는 식으로 구현할 수 있습니다. PG 연동 등을 해보신 분은 Exactly-Once 처리를 위해 Idempotency-Key를 요구하는 api를 보신적이 있을겁니다.
재처리 전략
카프카 컨슈머 쪽에서 메시지 처리 로직 중 예외를 만나면 어떤 식으로 처리할 지에 대해 WAS 단에서 설계해둘 수 있습니다. 주요 재처리 전략을 소개합니다.
Backoff

메시지 처리 실패 시 즉시 재시도하는 것이 아니라, 일정한 간격을 두고 재시도하도록 하는 방식입니다. 고정된 간격으로 재시도하는 FixedBackoff나 지수적으로 간격을 늘리는 ExponentialBackOff 전략 등을 채택할 수 있습니다.
실패 시 컨테이너 중지

메시지 처리 도중 특정 예외가 발생하면 컨슈머 컨테이너 자체를 중지시켜 더 이상의 메시지 소비를 멈추는 방식입니다. 이렇게 된 경우 고 수동으로 컨테이너를 재기동하기 전까지 컨슈머는 작동을 멈추고 이후 토픽도 소비하지 않습니다. 데이터 불일치나 비즈니스 로직 오류처럼 “치명적이고 자동 복구 불가능한 상황”에서 시스템을 보호하기 위해 사용합니다.
Dead Letter Queue
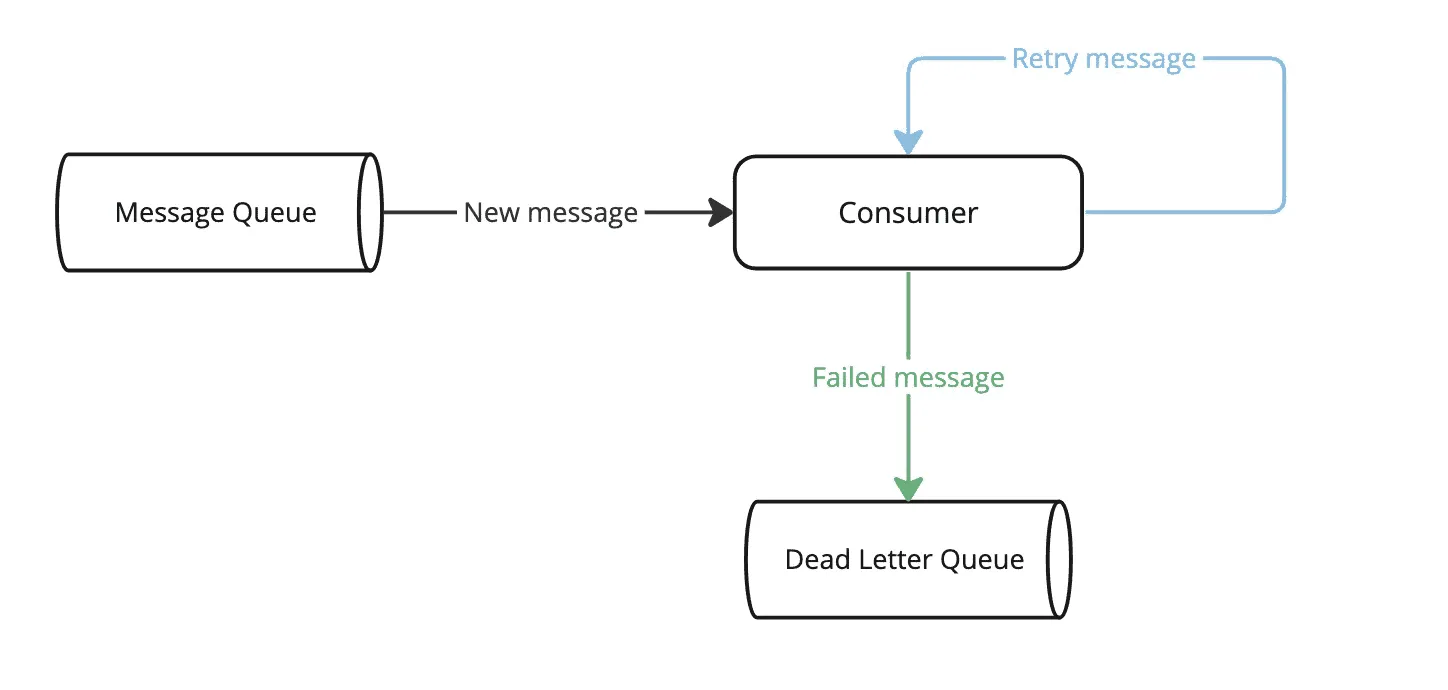
Dead Letter Queue 다이어그램 (이미지 출처)
데드 레터 큐는 임계까지 실패한 메시지에 대한 정보를 별도의 저장소(큐)에 보관하는 기법입니다. 카프카 특성 상 파티션 내에선 메시지를 순차 처리했었죠?
이 때 만약 한 메시지 처리에 장애가 생긴다면 그 파티션의 컨슈머 선택지는 2개입니다.
- 해당 메시지를 처리 성공할 때 까지 향후 메시지 처리 X (무한 재시도 or 실패 시 컨테이너 중지)
- 해당 메시지를 처리했다고 커밋하고 오프셋을 옮김
만약 2번 선택지를 선택할 경우 메시지 처리가 이루어지지 않고 유실될 수 있겠죠. 이 때 별도의 스토리지에 실패한 메시지에 대한 정보(토픽, 페이로드 등등)을 담아 저장하고 다음 메시지르 넘어간다면 향후 예외 원인이 해결 된 경우 관리자가 재처리를 할 수 있습니다.
DLQ는 패턴이라 여러 DB나 카프카 Topic 등 다양한 저장소를 선택해 구현할 수 있습니다.
Dead Letter Topic
데드 레터 토픽은 DLQ로 카프카 토픽을 사용하는 것을 뜻합니다. 특정 토픽의 실패 메시지를 별도의 다른 토픽에 보관해놓도록 합니다. 토픽 별로 일대일로 DLT를 만들 수도 있고, 별도의 그룹화 단위로 DLT를 따로 만들어서 관리할 수도 있습니다.
Spring Kafka 같은 Kafka 프로듀서 라이브러리에서는 데드 레터 토픽 기능을 지원해서 모든 처리 실패 전략의 종점에 유저가 설정하거나 혹은 자동으로 생성한 Dead Letter Topic으로 보내는 기능을 지원합니다.
출처
https://developer.confluent.io/courses/kafka-connect/error-handling-and-dead-letter-queues/
https://medium.com/techwasti/idempotent-kafka-consumer-442f9aec991e