시리즈의 지난 글에서 의존성 없이 자바 순수 코드로 TCP 소켓 서버를 만들어보았습니다.
소켓 통신 서버를 구현하며 응용 프로그램에서는 유의미한 요청/응답 체계를 갖추려면 TCP 프로토콜보다 상위의 규격화된 프로토콜이 필요하다는 것을 느꼈습니다.
앞으로 HTTP에 대해 아래와 같이 다루어보겠습니다.
- 순수 JDK 코드로만 소켓을 활용해 HTTP 서버를 대강 구현해보기
- HTTP 서버에게 있어 표준화된 명세의 필요성을 확인하기
- Servlet API가 무엇인 지 알아보기
- 직접 Servlet API를 구현하기
- 직접 만든 서블릿 컨테이너 기반 WAS 실행하기
이번 글에선 1~3번까지 진행해보겠습니다.
TCP는 어떻게 HTTP가 될까
HTTP는 다들 잘 아실테니 TCP가 어떻게 HTTP가 되는지 먼저 이해하고 넘어가겠습니다.
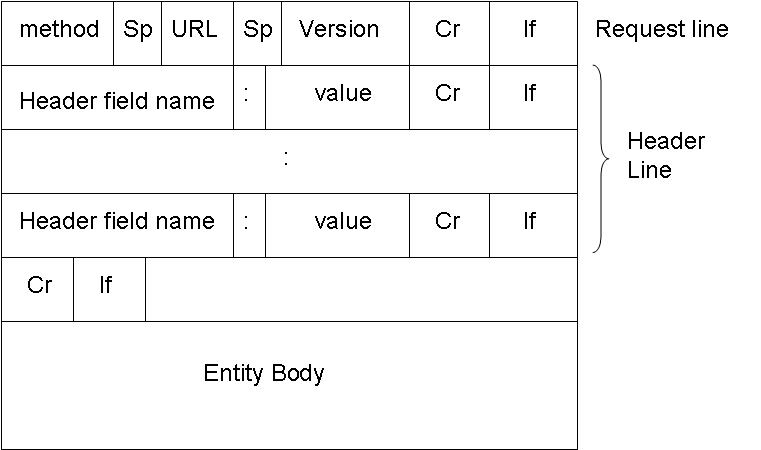
HTTP 패킷 구조 (이미지 출처)
TCP의 데이터에 저 구조대로 얹으면 HTTP가 됩니다. 눈으로 보는게 제일 빠르니 TCP 클라이언트로 HTTP 서버에 요청을 보내보겠습니다.

이런 식으로 CLI로 입력한 값을 그대로 TCP data에 담아 보내는 TCP 클라이언트 애플리케이션입니다.
아래 데이터를 그대로 TCP로 보내보겠습니다.
GET /hello HTTP/1.1
HOST:localhost

클라이언트 애플리케이션

TCP 세그먼트 1

TCP 세그먼트 2
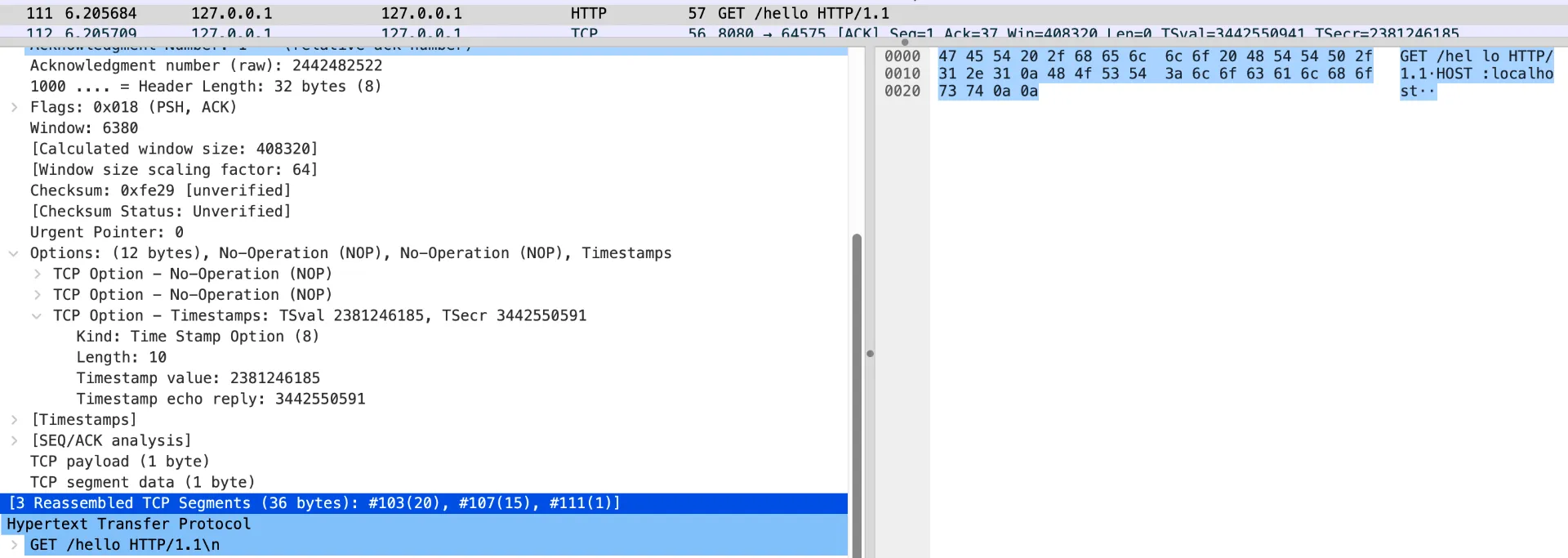
3번째 세그먼트(0a 개행문자)와 함께 Reassembled 된 HTTP 패킷
지난 글에서 알아봤 듯 TCP는 “요청”이나 “응답” 과도 같은 단위가 존재하지 않습니다. 제가만든 클라이언트 애플리케이션은 Enter 단위로 TCP 패킷을 쓰도록 만들어놨는데, 이에 따라 총 3줄이었던 데이터는 3개의 패킷으로 나뉘어 전송되었습니다.
WireShark 프로그램에서는 마지막 개행문자 TCP 패킷이 전송되는 순간 이 3개의 TCP 패킷이 HTTP 규격을 준수했고, HTTP 규격의 끝(마지막 개행문자)을 식별해 HTTP 패킷으로 재조립해주어 보여줍니다.
원시 HTTP 서버 구현
소스 코드는 위 링크에 있습니다.
소켓 부분은 스킵하겠습니다. 이 부분은 시리즈의 이전 글들을 읽어주시기 바랍니다.
요청 파서 (Request Parser)
먼저 소켓에서 InputStream을 받아서 Http요청으로 파싱해야합니다.
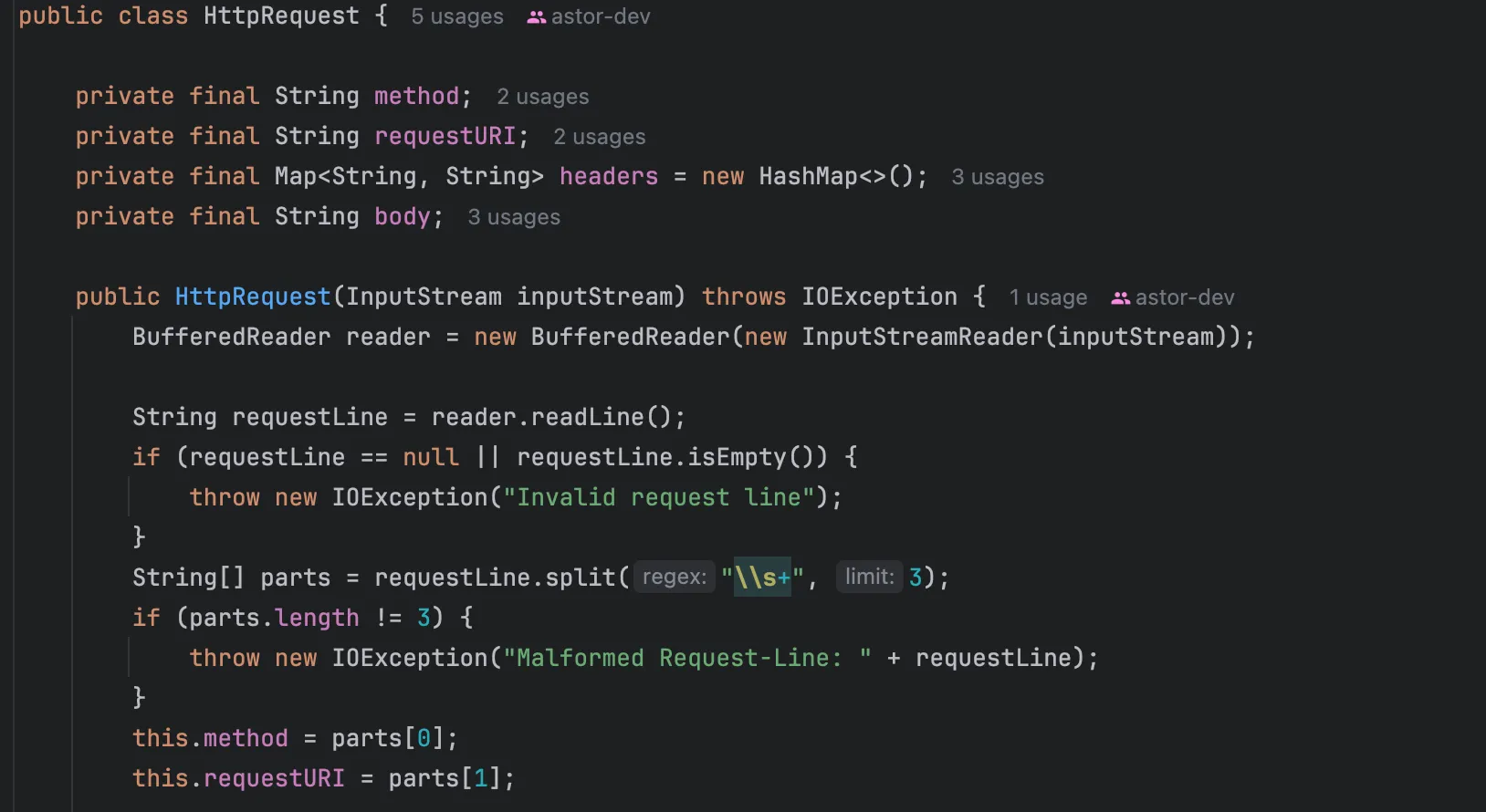
HTTP 첫 줄은 아래와 같았습니다.
METHOD[space]URI[space]Version\r\n간단한 구현을 위해 readLine을 사용했습니다. (실제 서비스에선 블로킹 위험이 있습니다)
첫줄을 읽고 METHOD/URI를 공백을 구분자로 식별합니다.
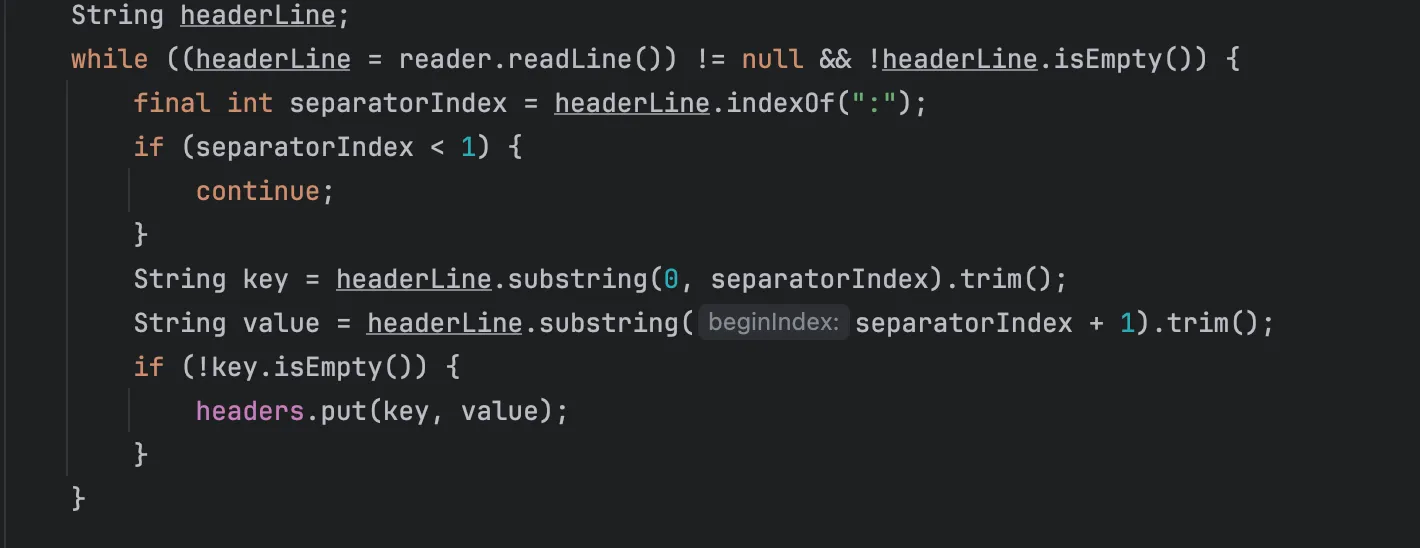
헤더도 똑같이 만듭니다. 헤더 명세는 아래와 같았습니다.
FIELD_NAME:VALUE\r\n
[...]
FIELD_NAME:VALUE\r\n
\r\n한줄을 읽었을 때 \r\n 이 나온다면 헤더 라인의 끝을 의미합니다. while 루프를 돌면서 파싱합니다.
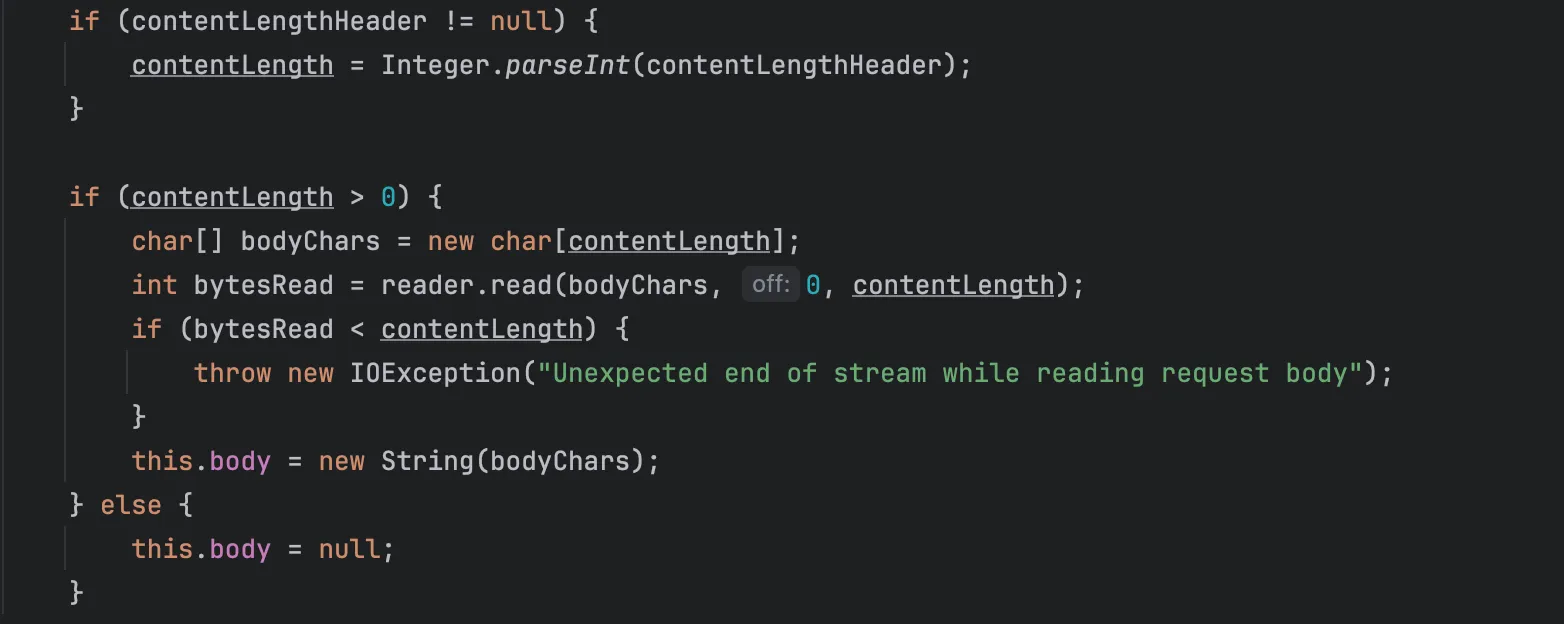
body는 content-length 헤더가 존재할 때 그 사이즈 만큼만 읽도록 구현해주었습니다.
응답 생성 (Response Generation)
소켓의 OutputStream을 직접 다루지 않고 HTTP 프로토콜에 맞추어 규격화된 값을 보내게 하는 클래스를 만들어줍니다.
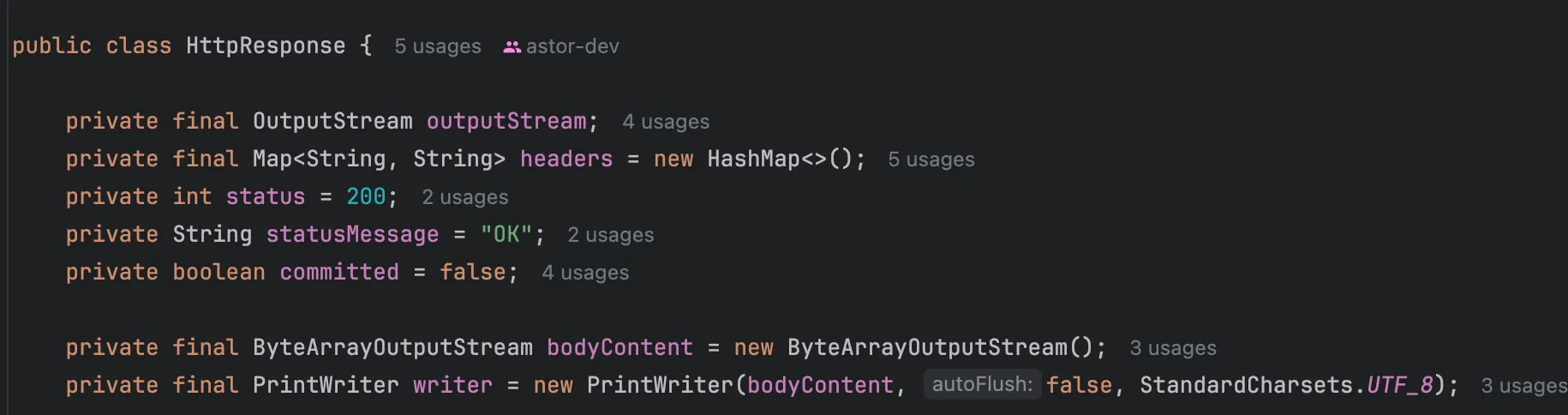
인스턴스 변수를 정의해둡니다. Body를 쓰기 위해 PrintWriter를 둡니다.
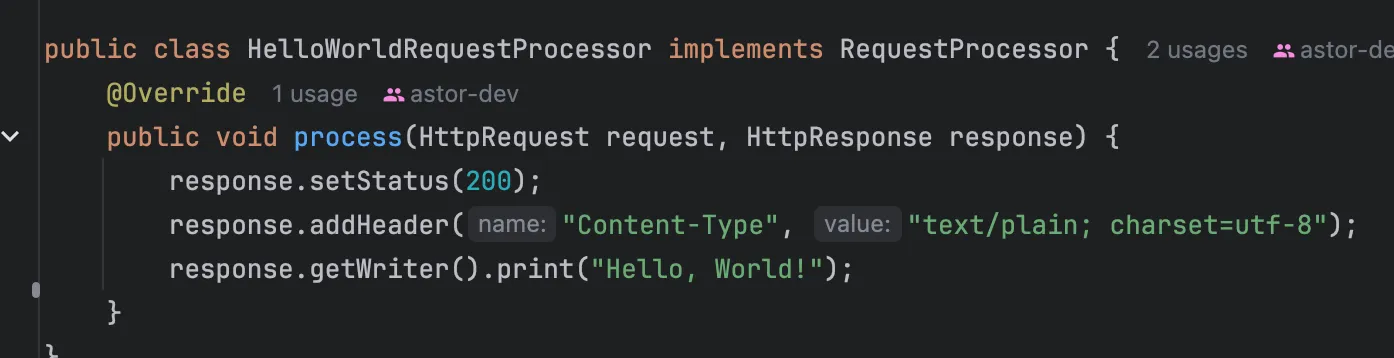
이런 식으로 사용할 수 있게 Getter와 Setter를 적당히 구현했습니다.
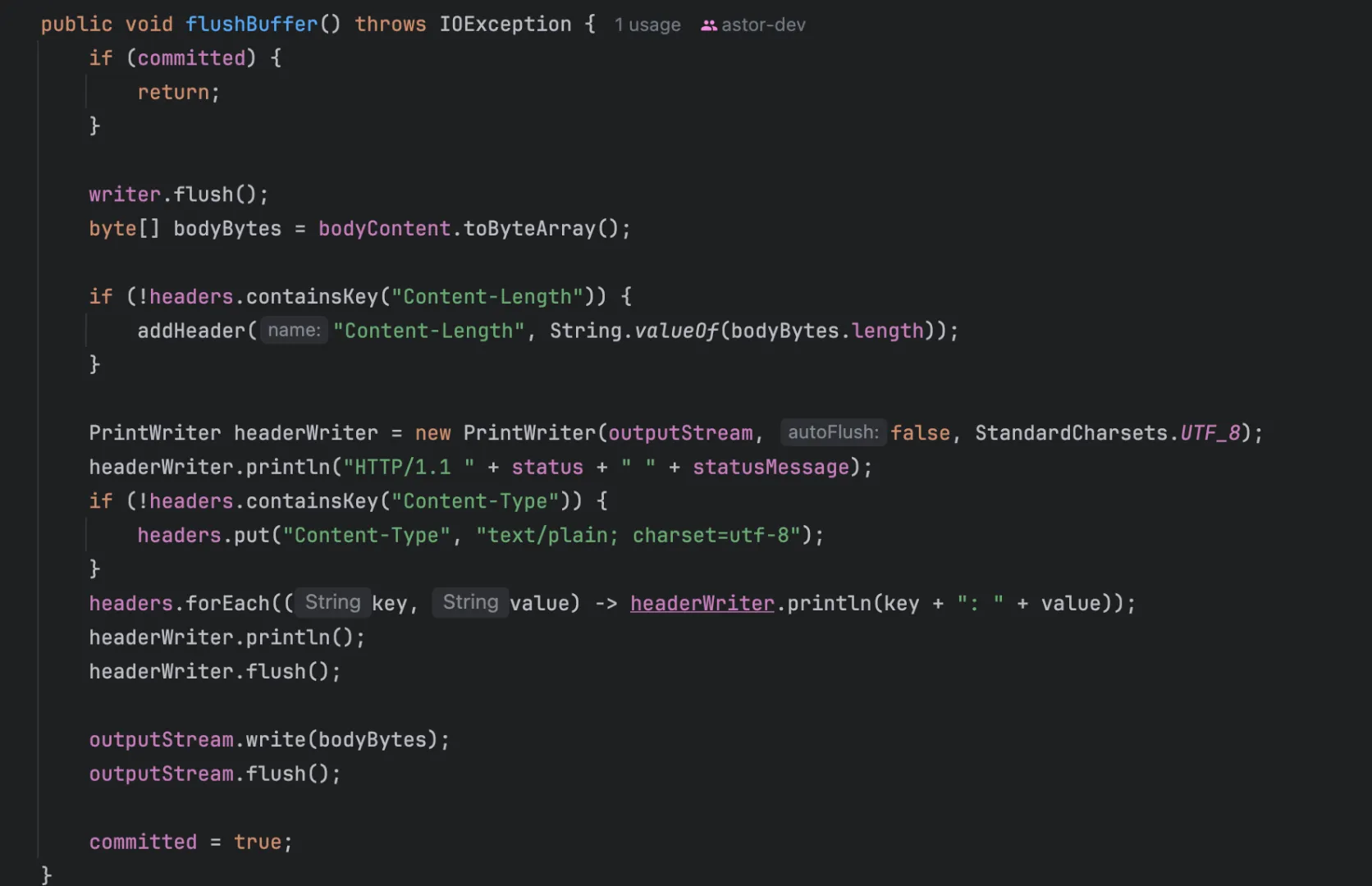
모든 처리가 끝난 후 사용될 flush 함수입니다.
응답을 전송할 때 body의 길이를 받아 Content-Length를 써줍니다. 초기 응답 규격을 맞춘 후 헤더 Map의 Key Value들을 규격에 맞는 문자열로 쓰고 개행 후 Body또한 더해 전송합니다.
소켓 핸들러
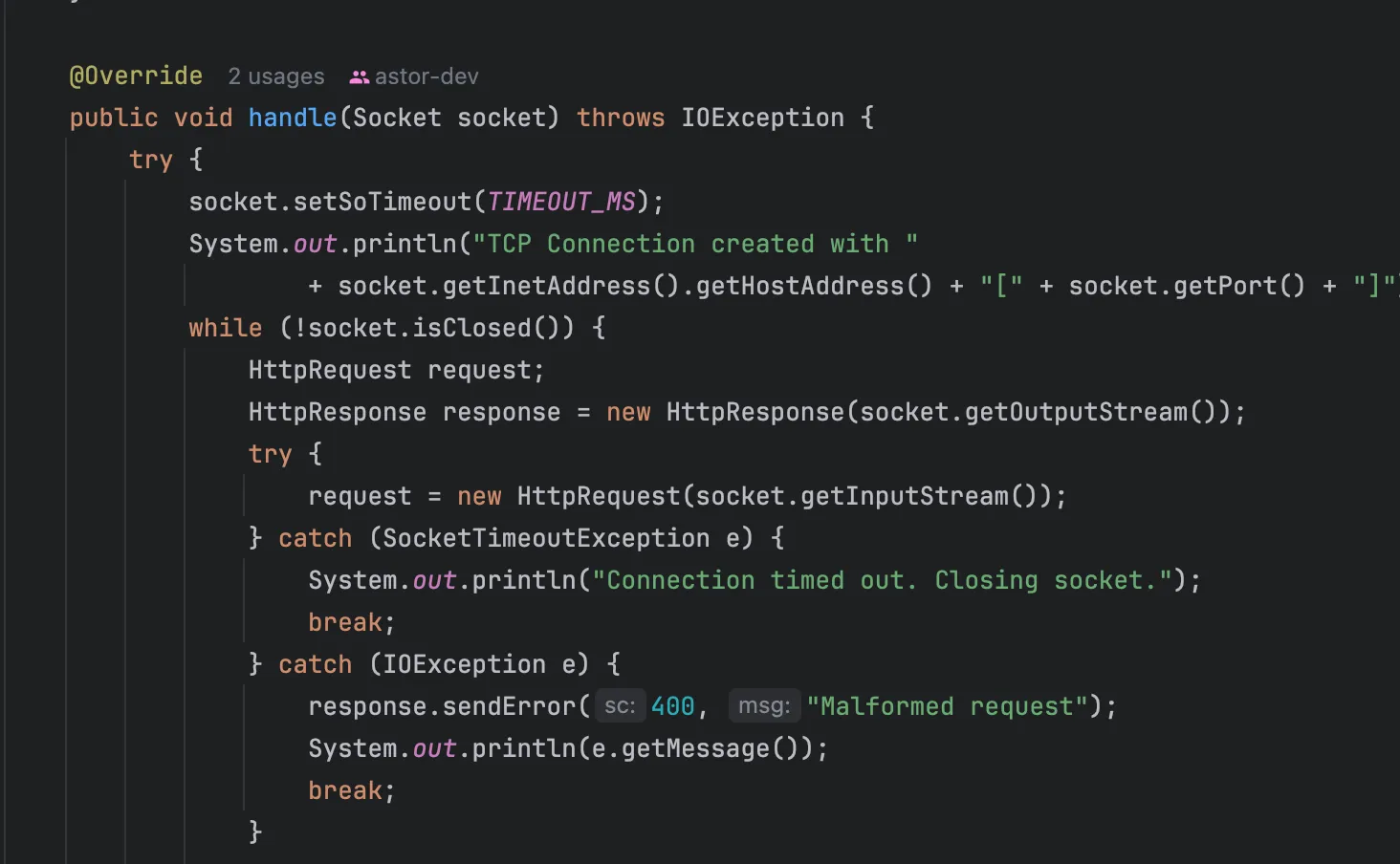
한번의 HTTP 통신을 마친 후 소켓을 닫아버리면 비효율적이기에 HTTP/1.1 명세의 KeepAlive를 구현해줍니다. 또한 url 별 처리 책임 분리를 위해 요청 핸들러에게 매핑또한 수행합니다.

클라이언트 요청의 헤더를 추출하여 Connection Header를 읽습니다.
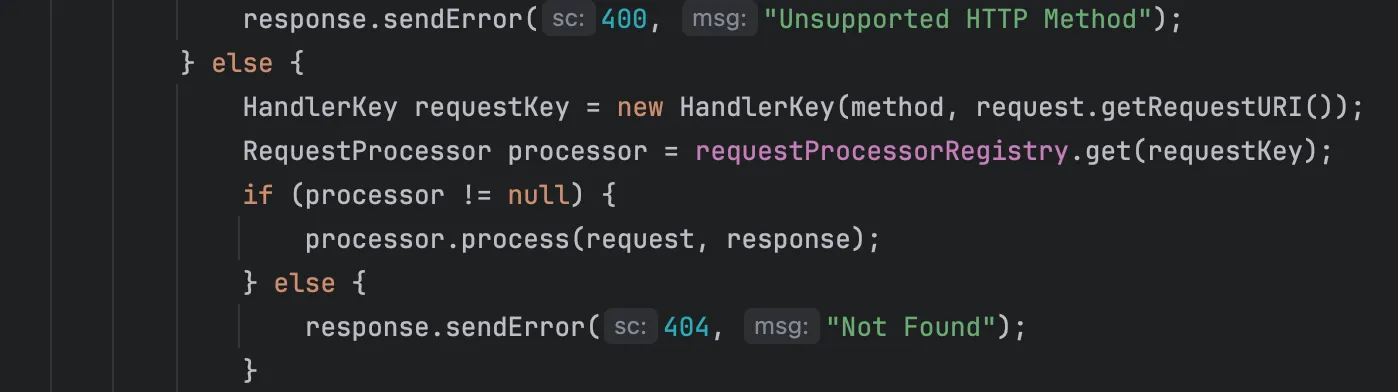
method와 uri를 조합해 Key를 만들었습니다. 적절한 처리용 클래스로 라우팅합니다.
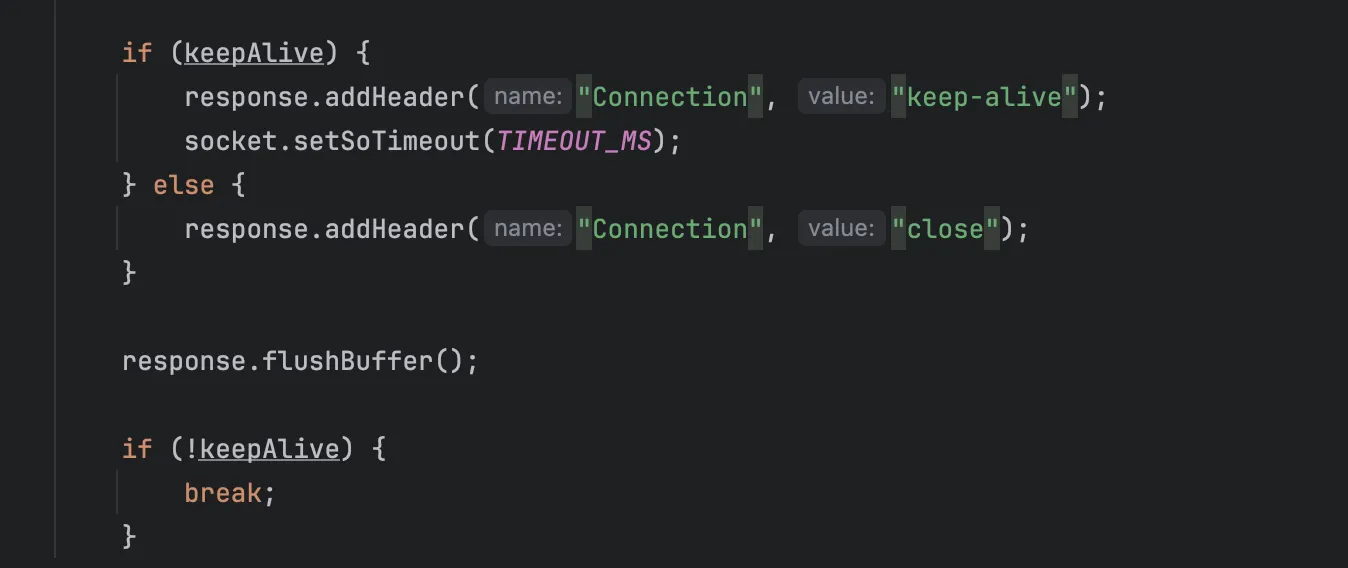
KeepAlive이면 서버측 헤더도 keep-alive를 붙여줍니다. flushBuffer로 응답을 보낸 후 KeepAlive가 아니라면 while 루프를 탈출합니다. 아닌 경우 일련의 과정을 다시 반복합니다.
최종적으로 소켓을 닫습니다.
한계 및 규격화된 명세의 필요성
직접 원시적인 HTTP를 구현해보니, 지나치게 자유롭다는 생각이 듭니다.
TCP 소켓 위에 데이터를 얹고, 응용 프로그램에서 그것을 해석하고 의미를 부여하는 식으로 HTTP 통신이 이루어 지게 됩니다.
즉, HTTP라는 프로토콜의 모든 규칙을 준수하고 처리하는 책임이 전적으로 애플리케이션 개발자가 지게됩니다.
- 요청 라인의 문법을 보장
- 헤더 파싱을 정확히 수행
- Content-Length나 Keep-Alive 등 규격에 맞는 헤더 처리
위와 같은 동작은 순수한 Java JDK에는 없습니다. 따라서 바닐라 Java 만으로는 작성한 Java 코드가 HTTP/1.1의 표준 명세를 엄밀하게 지킨다고 보장할 수가 없습니다.
그러면 Java 애플리케이션에서 무언가가 이 응용 프로토콜을 올바르게 준수하도록 보장해야 하지 않을까요? 즉 규격화된 명세가 필요해집니다.
가장 대표적인 것이 Eclipse 재단에서 관리하는 Servlet API입니다.
Jakarta Servlet API

서블릿 공식 문서
서블릿(Servlet)은 쉽게 말해, 응용계층 요청을 처리하고 응답을 생성하는 자바 기반 컴포넌트입니다. 즉, 개발자가 TCP 소켓이나 HTTP 프로토콜의 세부 구현을 직접 다루지 않아도, HTTP 요청을 받아 비즈니스 로직을 수행하고, 적절한 응답을 반환할 수 있게 해줍니다.
자주 오해하는데 중요한 점은, 서블릿은 바로 명세(specification)라는 것입니다. 바로 눈으로 보겠습니다.

의존성을 추가합니다.
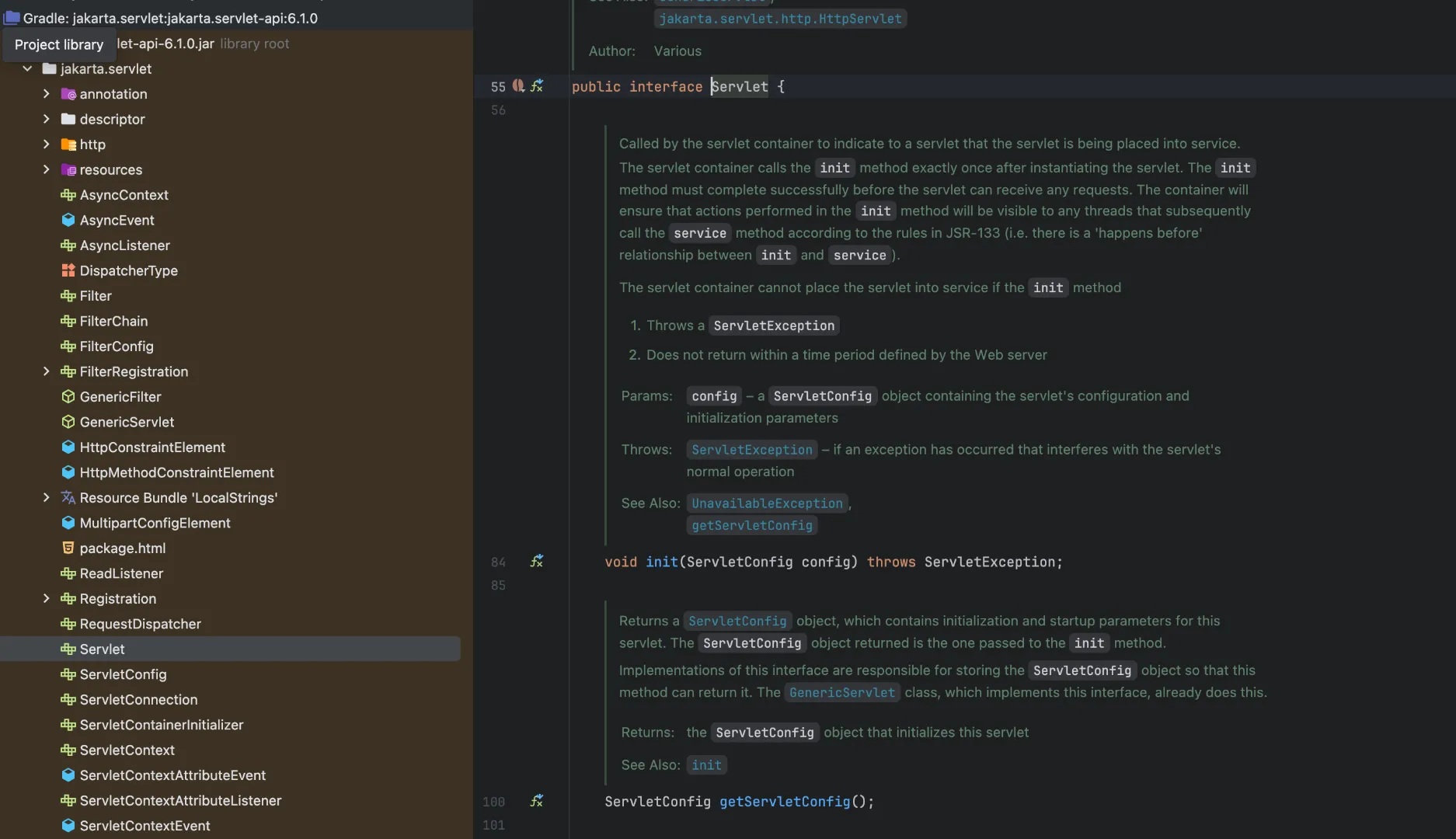
직접 소스를 들어가보면 전부다 interface로 구성되어있습니다. 서블릿 그 자체는 프로그래머가 응용계층 프로토콜을 다룰 때 사용할 인터페이스나 추상 클래스, 메서드들만 정의되어 있지 실질적인 로직은 거의 없습니다.
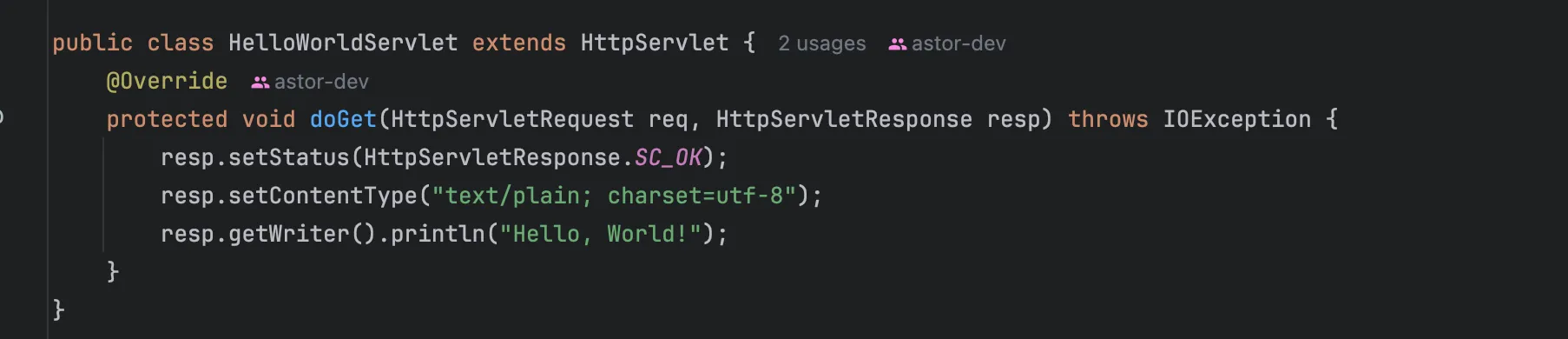
아까 제가 직접 구현했던 RequestProcessor 클래스를 Servlet Spec을 준수하게 만든다면 하나의 Servlet으로 대응시킬 수 있습니다.
직접 구현했던 Request나 Response Class도 유사하게, 더 엄밀하고 표준적으로 명세를 만들어 두었습니다.

자카르타 서블릿 공식 문서
이런 서블릿 인터페이스들을 모두 구현하여 서블릿을 실행시키는 환경을 제공하는 웹 서버 컴포넌트가 서블릿 컨테이너 입니다.
대표적인 서블릿 컨테이너로 Tomcat, Jetty, Undertow 등이 존재합니다.
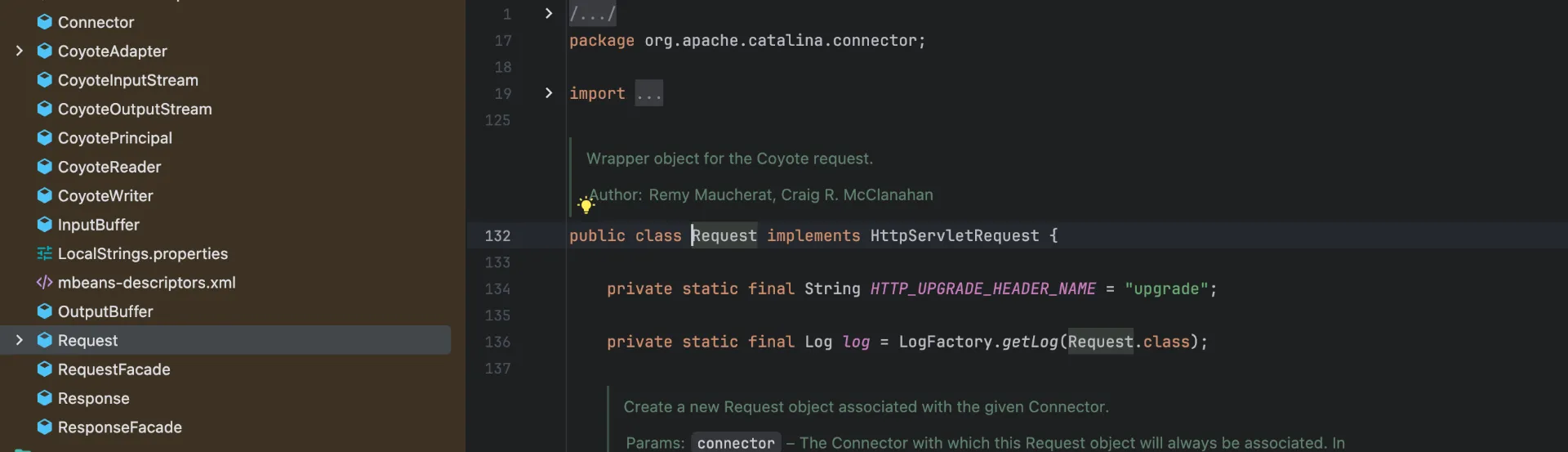
Tomcat의 org.apache.catalina.connector.Request
실질적인 Servlet Interface의 구현체는 각 컨테이너 의존성을 추가해야 확인할 수 있습니다.
다음 글에서는 서블릿 API 명세에 맞추어 직접 Servlet API 구현체를 만들어보고, 이렇게 만든 서블릿 컨테이너를 기반으로 하나의 WAS를 올려보도록 하겠습니다.