protobuf & gRPC Ecosystem
마이크로서비스 아키텍처가 자리 잡으면서 서버 간 통신 방식으로 gRPC가 주목받고 있습니다. 많은 아티클에서 “gRPC는 HTTP/1.1 기반 API보다 빠르다”라는 이야기를 접해보셨을 겁니다. 하지만 실제로 얼마나 빠른지, 어떤 상황에서 빠른지, 그리고 기존 벤치마크 결과가 얼마나 신뢰할 만한지는 직접 실험해보지 않으면 체감하기 어렵습니다.
이번 글에서는 클라우드 환경에 배포된 DB I/O, Kafka 등이 연결된 실제 애플리케이션을 대상으로 부하 테스트를 진행했습니다. 단순히 프로토콜 차원뿐만 아니라, 애플리케이션 내부의 풀 관리나 직렬화·역직렬화 오버헤드까지 반영된 실제 응답 시간 결과를 통해 gRPC를 보다 면밀히 살펴보겠습니다.
엄밀히 따지면 REST는 철학이자 스타일이지만, 글에서는 편의상 HTTP 1.1로 이루어지는 API를 REST API 라고도 부르겠습니다.
테스트 시나리오 정의
서버 사양
- 환경: GCP VM 1대
- 구성: Docker
- 런타임: Node.js 22.19.0
- 프레임워크: Nest.js
- 조건: 동일 서버에, 동일 모듈 의존성, 동일 로직 수행
시나리오 종류
- 큰 페이로드 + 단일 커넥션 + 고빈도 호출
- 작은 페이로드 + 단일 커넥션 + 고빈도 호출
- 큰 페이로드 + 다중 커넥션 + 고빈도 호출
- 작은 페이로드 + 다중 커넥션 + 고빈도 호출
- 큰 페이로드 + 로직 캐싱 + 단일 커넥션 + 한번에 다량 호출
기본 전제가 단일 커넥션인 이유는 gRPC 사용 환경 자체가 서버간 연결이기 때문에, 다량의 HTTP 커넥션을 맺고 끊을 일이 적습니다. 이미 HTTP 2.0 특성 상 같은 대상과의 요청은 이미 열려있는 풀을 활용해서 새로 연결하지 않고 처리하기에 더 실제상황과 유사한 비교가 가능합니다.
테스트 결과
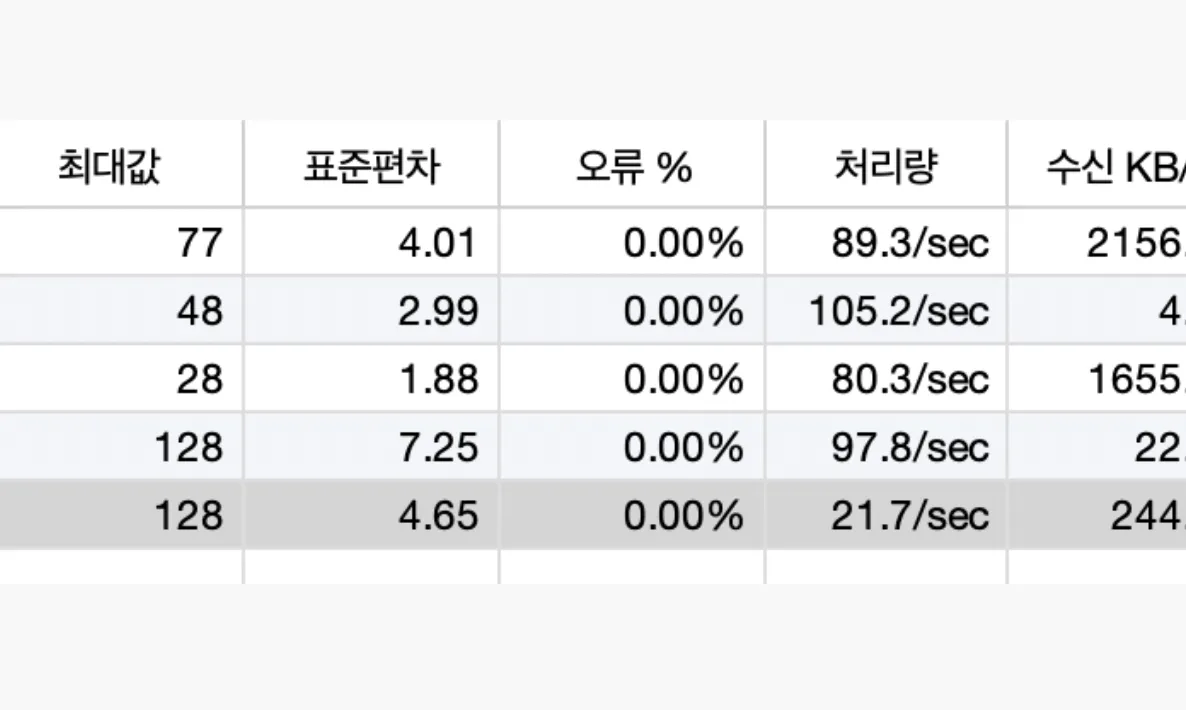
단일 커넥션 + 고빈도 호출

짧은 시간동안 고빈도 호출을 한 테스트 결과입니다. 아마 가장 통상적인 상황에서 확인할 수 있는 시나리오입니다.
표본수가 많지 않은 이유는 클라우드 개발 서버에 테스트를 한 점 + 임계가 넘어가면 DB나 cpu 장애로 딜레이 될 수 있어 통신 결과의 유의미한 비교가 되지 않아서입니다.
대략 처리량에 있어서 초당 10% 정도의 차이를 보입니다. 생각보다 드라마틱한 차이가 생기진 않는데, 이런 결과가 관측 되는 이유를 알기 위해 다음 테스트 결과를 보시겠습니다.
다중 커넥션 + 고빈도 호출

설명에 앞서 이런 상황은 실제 서비스에선 생기지 않습니다!!
HTTP/1.1 요청과 유사하게, 100명의 사용자가 각각 커넥션을 새로 열고 단 한 번만 요청을 보내는 상황을 가정했습니다. 이렇게 되면 gRPC가 본래 제공하는 HTTP/2.0 기반 멀티플렉싱의 이점을 전혀 활용할 수 없습니다. 요청마다 매번 핸드셰이킹을 수행하고, 즉시 FIN으로 연결을 종료하기 때문입니다.
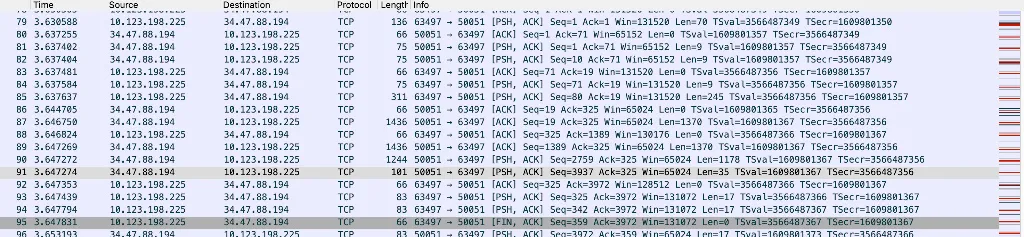
WireShark에서 확인한 해당 시나리오의 패킷입니다. 한 요청 당 핸드쉐이킹을 하고 바로 FIN으로 끊는 모습입니다.
이 케이스에서는 무려 HTTP 요청보다 2배 이상 느렸습니다. HTTP 1.1도 마찬가지로 핸드 쉐이킹을 할 텐데 왜 그럴까요?
차이는 바로 실제 애플리케이션 내부에서 gRPC를 관리하는 로직 자체가 HTTP 1.1에 비해 상대적으로 무겁다는 점입니다.
- 프로토콜 버퍼 직렬화/역직렬화 처리
- gRPC 채널 및 스트림 관리
- 추가적인 메타데이터 및 프레임 관리
이러한 부가적인 비용이 단발성 요청 시에는 오히려 REST보다 불리하게 작용하게 됩니다.
코드로 보겠습니다.

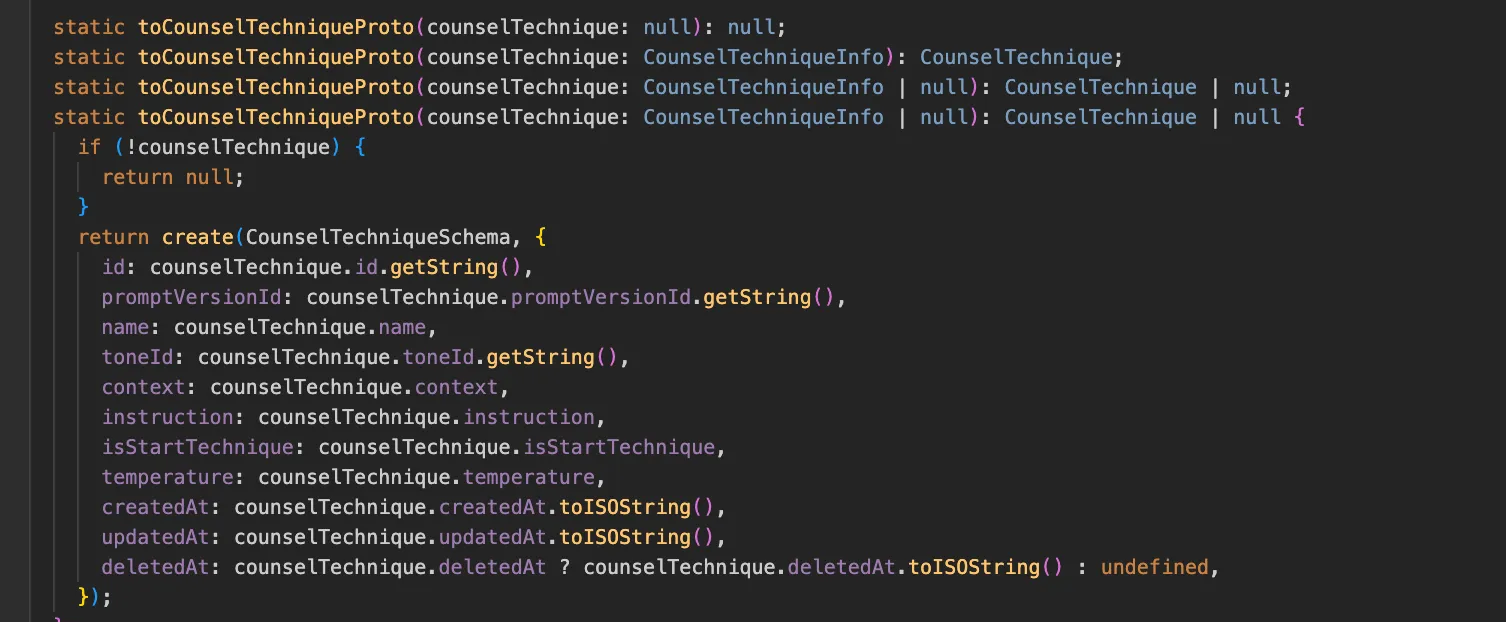
typescript에서의 dto class -> rpc용 proto class 매핑 (bufbuild)
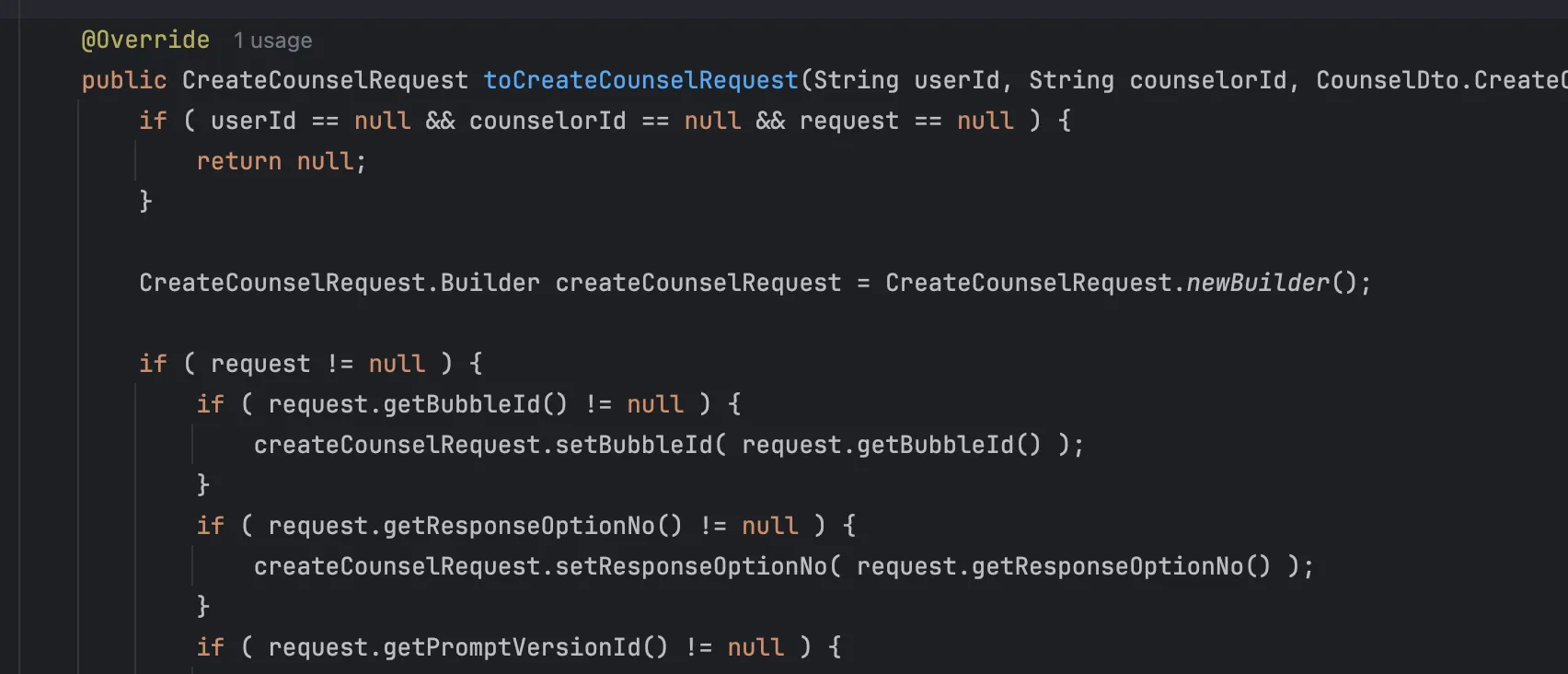
Java에서의 dto class -> rpc용 proto class 매핑 (bufbuild)(mapstruct 통해 자동 impl)
gRPC는 서버 내부에서 사용하는 JSON 직렬화 가능한 응답 클래스를 그대로 반환할 수 없습니다. 대신, 각 언어별 프로토콜 버퍼 전용 라이브러리로 생성된 클래스에 매핑한 뒤에야 전송할 수 있습니다. 즉, 애플리케이션 내부 VO나 DTO를 프로토콜 버퍼용 객체로 변환하는 매핑 과정이 필수적으로 들어갑니다.
흔히 gRPC의 장점으로 “JSON 대비 빠른 직렬화 성능”이 언급되지만, 실제 구현 단에서는 이 매핑 로직이 추가되면서 오히려 직렬화 이점이 일부 상쇄되는 오버헤드가 발생할 수 있습니다.
이를 통해 알 수 있는 점은, 통신 프로토콜 자체는 빠르더라도 실제 애플리케이션에서는 매핑이나 내부 처리 로직에서 발생하는 추가 오버헤드 때문에 성능적 이점이 그대로 보장되지는 않는다는 것입니다.
큰 페이로드 + 로직 캐싱 + 단일 커넥션 + 한번에 다량 호출

큰 페이로드를 메모리에 캐싱해놓고, 부하테스트를 진행해보았습니다. 요청을 받자마자 바로 응답하기에 순수하게 직렬화 성능만 비교할 수 있었습니다. 속도면에선 10% 정도의 이점을 갖는 모습입니다.
실험의 한계
저희 사이드 프로젝트엔 스트리밍 로직이 없어서 스트리밍에 대한 테스트를 진행하지 못했습니다.
또한 직렬화 부분에선 CPU 오버헤드 차이가 꽤나 있을 것으로 보이는데, 개발 서버엔 모니터링을 안해놓아서 확인할 수 없었습니다.
이 부분은 기회가 되면 또 해보겠습니다.
결론
이번 실험을 통해 확인한 바는 다음과 같습니다.
gRPC는 항상 빠른 것이 아니다.
단일 커넥션을 유지하면서 고빈도 요청이 발생하는 일반적인 서버 간 통신 시나리오에서는 gRPC가 REST 대비 소폭(약 10% 내외)의 성능 이점을 보여주었습니다. 그러나 요청을 매번 새로운 커넥션으로 처리하는 비현실적인 시나리오에서는 오히려 REST보다 훨씬 느려지는 결과를 확인할 수 있었습니다.
프로토콜 자체의 이점과 애플리케이션 레벨 오버헤드를 구분해야 한다.
gRPC는 HTTP/2 기반 멀티플렉싱과 효율적인 직렬화 방식을 제공하지만, 실제 애플리케이션 구현에서는 DTO → Proto 객체 매핑, 채널 관리, 메타데이터 처리 등 부가 로직이 추가되어 성능적 이점이 상쇄될 수 있습니다.
테스트 결과는 ‘조건부 우위’를 보여준다.
캐싱된 페이로드처럼 순수 직렬화 성능만 비교할 경우 gRPC의 장점이 뚜렷했지만, 실제 DB I/O, Kafka 연동 등 다양한 요소가 얽힌 애플리케이션 환경에서는 그 차이가 제한적이었습니다.
따라서 gRPC는 마이크로서비스 간 내부 통신, 스트리밍, 고빈도 요청 시에 적합한 선택이 될 수 있지만, 외부 API 제공, 단발성 호출, 기존 서버와의 통합이 중요한 경우에는 REST가 여전히 유효한 대안입니다.
또한 gRPC를 사용하기 위해 필연적으로 따라오는 protobuf 관리 문제가 있기 때문에, 도입을 고려하신다면 좀 더 실무적으로 충분한 검토가 필요할 것입니다.