*본 시리즈는 필자가 Confluent의 문서들과 강의 한번에 끝내는 Kafka Ecosystem, 이외의 여러 자료들을 통해 학습한 내용을 기반으로, 응용 서비스 개발자들이 카프카를 사용하는데 필요한 개념과 코드들을 컴팩트하게 모아 정리하는 것을 취지로 합니다. 따라 인프라적인 내용이나 DevOps 관점에서의 깊이 있는 탐구는 다루지 않습니다.
시작하며: 왜 Kafka인가?

현대의 소프트웨어는 점점 더 복잡해지고, 비즈니스가 성장함에 따라 관여하는 이해관계자와 기능의 수도 늘어납니다. 자연스럽게 서비스의 개수는 많아지고, 각 서비스는 서로를 호출하며 거미줄처럼 얽히게 됩니다. 이러한 강한 결합 구조는 하나의 작은 장애가 시스템 전체로 번지는 연쇄 장애를 일으키기 쉽고, 기술 부채가 쌓이며 새로운 기능을 추가하거나 변경하는 것을 극도로 어렵게 만듭니다.
이러한 복잡성을 제어하기 위해 아키텍처 설계 역사에서는 오래전부터 시스템 간의 의존성을 끊어내 느슨한 결합(Loose Coupling) 을 만들려는 노력이 계속되어 왔고, 그 중심에는 메시지 큐(Message Queue) 를 활용한 디자인 패턴이 있었습니다. 메시지 큐는 중간에서 메시지를 보관했다가 전달하는 버퍼 역할을 함으로써, 생산자(Producer)와 소비자(Consumer) 패턴으로 시스템을 분리하여 시스템 전체의 안정성을 높이는 효과적인 해법이었습니다.
하지만 데이터가 폭발적으로 많아지는 오늘날, 기존 메시지 큐만으로는 한계가 명확해졌습니다.
- 데이터 유실 문제: 장애가 발생했을 때 중요한 메시지가 그대로 사라져 버릴 위험이 있었습니다.
- 어려운 병렬 처리: 처리할 메시지가 많아져서 컨슈머 서버를 여러 대 늘리면, 같은 메시지를 여러 서버가 중복으로 처리하는 문제가 생겼습니다. 기존 메시지 큐에는 ‘컨슈머 그룹’ 같은 개념이 없어 누가 어떤 메시지를 처리할지 똑똑하게 관리해주지 못했기 때문입니다.
이럴 때 주요하게 사용되는 기술이 아파치 카프카(Apache Kafka) 입니다. 카프카 공식 문서는 스스로를 이렇게 소개합니다.

“아파치 카프카는 고성능 데이터 파이프라인, 스트리밍 분석, 데이터 통합 및 미션 크리티컬 애플리케이션을 위해 수천 개의 회사에서 사용하는 오픈소스 분산 이벤트 스트리밍 플랫폼입니다.”출처:Apache Kafka 공식 홈페이지
이 ‘이벤트 스트리밍 플랫폼’이라는 철학 덕분에, 카프카는 데이터를 절대 유실하지 않는 영속성을 보장하고, ‘컨슈머 그룹’ 기능을 통해 여러 대의 컨슈머가 중복 없이 메시지를 나눠 처리하는 완벽한 병렬 처리를 가능하게 해줍니다.
카프카 핵심 개념과 아키텍처
분산 커밋 로그
카프카를 이해하는 가장 중요한 키워드는 분산 커밋 로그(Distributed Commit Log) 입니다. 말이 좀 어려운데, 사실 여러분이 자주 쓰는 데이터베이스의 트랜잭션 로그와 똑같은 개념이라고 생각하면 쉽습니다.
데이터베이스가 모든 변경 사항(INSERT, UPDATE, DELETE)을 안전한 로그 파일에 순서대로 착착 쌓아두는 것처럼, 카프카도 모든 데이터(이벤트)를 순서가 보장된, 절대 바뀌지 않는(Immutable) 로그의 형태로 디스크에 차곡차곡 기록(Append-only)합니다. 이런 단순한 구조 덕분에 디스크에 데이터를 쓰는데도 엄청난 처리량을 보여주고, 데이터의 영속성까지 확실히 보장하는 거죠
이렇게 데이터를 로그 형태로 쌓기 때문에, 일반적인 메시지 큐와 다르게 데이터를 소비해도 바로 삭제되지 않습니다. (물론, 설정에 따라 오래된 데이터는 주기적으로 지워집니다.) 그럼 데이터를 소비하는 쪽에서는 어떻게 자기가 어디까지 읽었는지 알 수 있을까요?
컨슈머 (Consumer) 와 오프셋 (Offset)
바로 여기서 컨슈머(Consumer) 가 등장합니다. 컨슈머는 토픽에서 데이터를 가져와 사용하는 클라이언트 애플리케이션입니다. 우리가 띄운 스프링 서버 인스턴스 1개가 하나의 컨슈머가 될 수 있죠. 중요한 점은, 카프카는 컨슈머가 데이터를 얼마나 가져갔는지 전혀 신경 쓰지 않는다는 겁니다.
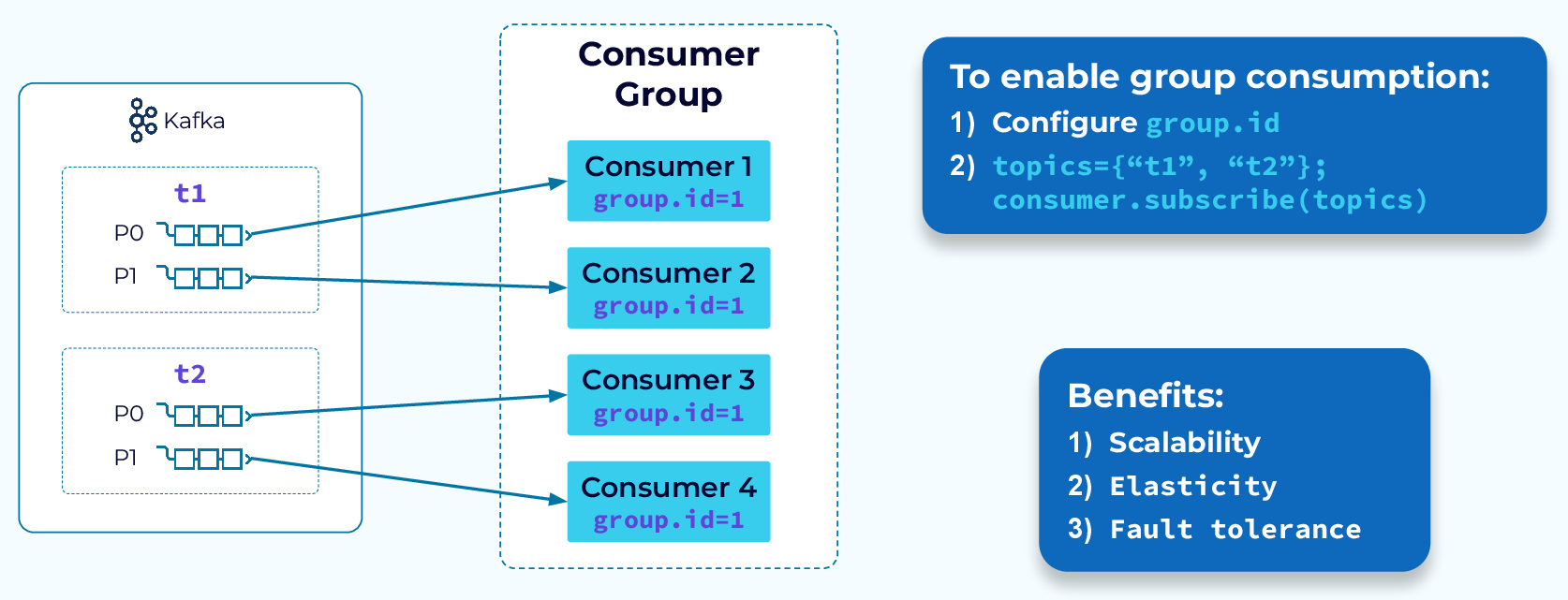
대신 컨슈머 스스로가 “아, 나 여기까지 읽었어!” 하고 자신이 읽은 데이터의 위치를 ‘오프셋(Offset)‘이라는 지표로 기록하고 기억합니다. 덕분에 여러 다른 컨슈머들이 각자 다른 위치에서 데이터를 읽어갈 수 있고, 문제가 생기면 특정 오프셋으로 돌아가 데이터를 다시 읽어오는 것도 가능해지죠.
컨슈머들은 보통 ‘컨슈머 그룹’ 이라는 팀 단위로 움직이는데, 하나의 팀에 속한 컨슈머들은 데이터를 중복 없이 나눠서 병렬로 처리하는 역할을 맡습니다.
컨슈머 그룹 활용
이 ‘컨슈머 그룹’ 기능이 왜 그렇게 유용한지 마이크로서비스 환경을 예로 생각하면 알 수 있습니다.
보통 하나의 서비스도 안정성을 위해 여러 개의 서버 인스턴스로 띄워두죠. 이때 order-created 같은 이벤트가 발생하면, ‘결제 서비스’도 처리해야 하고 ‘알림 서비스’도 처리해야 합니다. 여기서 중요한 건, 각 서비스별로 딱 한 번씩만 처리되어야 한다는 점이죠.
기존 메시지 큐 방식이라면 이게 꽤나 머리 아픕니다. 모든 인스턴스에 메시지를 다 보내면(Broadcast), ‘결제 서비스’ 서버 3대가 전부 똑같은 결제를 3번 시도하는 대참사가 일어나겠죠. 이걸 막으려면 서비스 내부에서 자체적으로 리더를 뽑아서 ‘대표’ 인스턴스 하나만 일하도록 복잡한 로직을 또 짜야만 했습니다.
하지만 카프카는 이걸 ‘컨슈머 그룹’ 하나로 깔끔하게 해결합니다. 그냥 ‘결제 서비스’ 전체를 하나의 컨슈머 그룹으로, ‘알림 서비스’ 전체를 또 다른 컨슈머 그룹으로 묶어주기만 하면 끝입니다. 카프카가 알아서 각 그룹에게 메시지를 한 번씩 전달하고, 그룹 내에서는 단 하나의 인스턴스만 그 메시지를 처리하도록 분배해주거든요. 골치 아픈 리더 선출 같은 걸 전혀 고민할 필요가 없어 매우 편하죠.
프로듀서 (Producer)
지금까지 데이터를 ‘소비’하는 컨슈머에 대해 알아봤으니, 이제 반대로 이 데이터를 ‘생산’하는 주체에 대해 알아볼 차례입니다. order-created 같은 이벤트는 대체 누가, 어떻게 만드는 걸까요? 바로 여기서 프로듀서(Producer) 가 등장합니다.
프로듀서는 카프카 토픽으로 데이터를 생성해서 보내는 모든 클라이언트 애플리케이션을 의미합니다. 예를 들어, 사용자가 주문을 완료했을 때 ‘주문 서비스’가 order-created 이벤트를 만들어서 카프카로 쏘는 역할을 한다면, 이 ‘주문 서비스’가 바로 프로듀서가 되는 거죠.
지금까지 설명한 프로듀서와 컨슈머가 바로 카프카 생태계에서 우리 WAS가 맡는 역할입니다. 프로듀서랑 컨슈머 쪽에서는 저희가 설정해야하는 값들이 많은데, 이를 위해서는 아래 토픽, 파티션 등 개념을 알아야 하기에 다음 포스트로 다뤄보겠습니다.
토픽 (Topic) 과 파티션 (Partition)
그렇다면 프로듀서가 발행하고, 컨슈머가 읽어오는 그 ‘커밋 로그’는 대체 어디에 쌓이는 걸까요? 그 데이터 저장소가 바로 토픽(Topic) 입니다.
토픽은 데이터를 구분하기 위한 카테고리 또는 채널 이름입니다. DB의 테이블처럼, 프로듀서는 order-events 같은 특정 토픽에 데이터를 보내고, 컨슈머는 이 토픽을 ‘구독’해서 데이터를 가져오는 거죠.
그런데 대용량 데이터가 하나의 토픽에 전부 쌓이면 너무 느려지지 않을까요? 그래서 카프카는 토픽을 여러 개의 작은 조각으로 나누는데, 이것이 바로 파티션(Partition) 입니다.
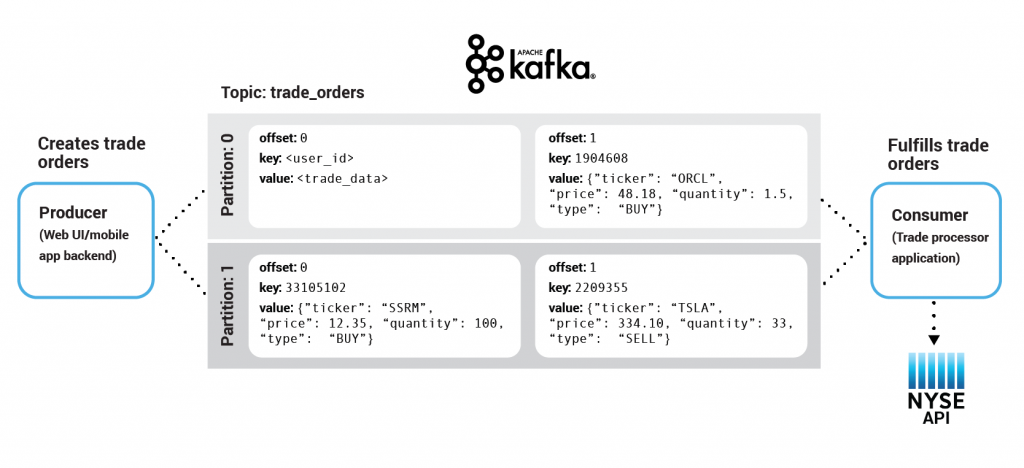
파티션으로 토픽을 나누면, 여러 컨슈머가 각 파티션에 동시에 접근해 데이터를 병렬로 처리할 수 있습니다. 즉, 파티션의 개수가 곧 그 토픽의 최대 병렬 처리량이 됩니다.
브로커 (Broker) 와 클러스터
그럼 이 토픽과 파티션이라는 데이터 저장소는 실제로 어디에 위치할까요? 바로 브로커(Broker) 입니다.
![]()
출처 (https://newsletter.systemdesigncodex.com/p/introduction-to-kafka)
브로커는 카프카 클러스터를 구성하는 서버 한 대 한 대를 의미합니다. 반대로 클러스터는 브로커의 집합입니다. 우리가 만든 order-events 토픽을 3개의 파티션으로 쪼갰다고 상상해 보세요. 카프카는 부하를 분산하고 안정성을 높이기 위해 이 파티션들을 여러 브로커에 나눠서 저장합니다.
파티션 0은 브로커 1번 서버에
파티션 1은 브로커 2번 서버에
파티션 2는 브로커 3번 서버에
이렇게 토픽의 파티션들을 여러 브로커에 분산시키는 구조 덕분에, 하나의 서버에 트래픽이 몰리는 것을 막고 전체 처리량을 극대화할 수 있습니다.
리더 브로커
여기서 중요한 규칙이 하나 있습니다. 각 파티션마다 ‘책임자’ 브로커가 한 명씩 정해지는데, 이 책임자가 바로 리더(Leader) 입니다. 특정 파티션에 대한 모든 데이터 읽기/쓰기 요청은 반드시 해당 파티션의 리더 브로커를 통해서만 이루어져야 합니다.
만약 아무 브로커나 파티션에 데이터를 쓸 수 있다면 데이터 순서가 뒤죽박죽 엉망이 되겠죠? 그래서 카프카는 각 파티션마다 단 하나의 리더를 두어 데이터의 정합성과 순서를 보장하는 것입니다.
브로커 실제 구성 예시
개념은 알겠는데, 그래서 실제로 어떻게 돌아가는지 감이 잘 안 오실 수 있습니다. 아주 구체적인 시나리오를 하나 설정해 봅시다.
- 카프카 클러스터: 3대의 서버로 구성 (브로커 1, 브로커 2, 브로커 3)
- 토픽:
order-events라는 이름의 토픽 - 파티션 개수: 2개 (파티션 0, 파티션 1)
- 복제 계수(Replication Factor): 3 (하나의 파티션은 원본 1개 + 복제본 2개, 총 3개가 존재)
이 설정은 “모든 파티션은 모든 브로커에 하나씩 존재하여, 어떤 서버가 다운돼도 데이터를 안전하게 지킨다”는 의미입니다..
step 1. 리더와 팔로워 자동 선출클러스터가 구성되면, 카프카는 각 파티션의 ‘책임자’인 리더(Leader) 와 ‘백업’인 팔로워(Follower) 를 자동으로 분배합니다. 이때 중요한 점은 리더를 한 브로커에 몰아주지 않고 최대한 골고루 분산시킨다는 것입니다.
예를 들어, 아래와 같이 역할이 정해질 수 있습니다.
| 파티션 0 | 파티션 1 | |
|---|---|---|
| 브로커 1 | 리더 (Leader) | 팔로워 (Follower) |
| 브로커 2 | 팔로워 (Follower) | 리더 (Leader) |
| 브로커 3 | 팔로워 (Follower) | 팔로워 (Follower) |
이렇게 되면
파티션 0에 대한 모든 읽기/쓰기 요청은 오직 브로커 1만 처리합니다.
파티션 1에 대한 모든 읽기/쓰기 요청은 오직 브로커 2만 처리합니다.
브로커 1이 파티션 0에 새로운 데이터를 받으면, 즉시 브로커 2와 브로커 3에 있는 파티션 0의 팔로워들에게 데이터를 복제해서 나눠줍니다. 브로커 2 역시 파티션 1의 리더로서 동일한 작업을 수행하죠.
만약 파티션 1의 리더인 브로커 2가 갑자기 다운되면 어떻게 될까요?
- 클러스터의 지휘자(주키퍼/KRaft)가
브로커 2의 장애를 즉시 감지합니다. - 지휘자는
파티션 1의 팔로워였던브로커 1과브로커 3중에서 새로운 리더를 선출합니다. (여기서는브로커 3이 새로운 리더가 되었다고 가정해 봅시다.) - 클러스터의 상태는 아래와 같이 실시간으로 변경됩니다.
| 파티션 0 | 파티션 1 | |
|---|---|---|
| 브로커 1 | 리더 (Leader) | 팔로워 (Follower) |
| 브로커 2 | (서버 다운) | (서버 다운) |
| 브로커 3 | 팔로워 (Follower) | 새로운 리더 (New Leader) |
이제부터 파티션 1에 데이터를 보내려던 프로듀서와 데이터를 읽으려던 컨슈머는 자동으로 새로운 리더인 브로커 3으로 접속하게 됩니다. 이 모든 과정이 수 초 내에 자동으로 이루어지기 때문에, 서비스 중단 없이 안정적으로 데이터를 계속 처리할 수 있는 것입니다.
여기서 인프라적으로 들어가면 ISR(In-Sync Replica)이나 EOS(Exactly-Once Semantics) 모드 등 동기화에 대한 처리가 있지만 시리즈 취지에 부합하지 않아서 넘어가겠습니다. 궁금하신 분들은 원리가 재밌으니 알아보셔도 좋을 거 같네요.
이처럼 카프카는 파티션 단위로 리더와 팔로워를 여러 브로커에 교차로 분산시키는 영리한 설계를 통해, 부하 분산과 고가용성(장애 대응 능력) 이라는 두 마리 토끼를 동시에 잡습니다.
카프카의 활용 사례
카프카의 활용사례에 대해서는 많은 아티클이 있지만, 지금까지 배운 이론의 활용을 볼 겸 흥미롭게 본 것들을 공유합니다.
토스 뱅크에서의 사례
원문: 은행 최초 코어뱅킹 MSA 전환기 (feat. 지금 이자 받기)
복잡한 테이블에 걸친 트랜잭션을 비동기로 전환해 성능 최적화를 한 사례입니다. “DB 쓰기가 지연됐을 때 고객 잔액에 실시간으로 문제가 생기는가?” 를 기준으로 즉시성이 보장되어야 하는 작업과, 세금 처리처럼 나중에 처리해도 괜찮은 작업을 구분했습니다.
카카오에서의 사례
재밌게 본 영상이라 공유합니다. 앞서 나온 EOS 등의 개념이나 구현법 등을 설명합니다.