Kafka For Developer (4)
-
1. 아파치 카프카란? 기본 개념 및 철학
\*본 시리즈는 필자가 Confluent의 문서들과 강의 한번에 끝내는 Kafka Ecosystem, 이외의 여러 자료들을 통해 학습한 내용을 기반으로, 응용 서비스 개발자들이 카프카를 사용하는데 필요한 개념과 코드들을 컴팩트하게 모아 정리하는 것을 취지로 합니다. 따라 인프라적인 내용이나 DevOps 관점에서의 깊이 있는 탐구는 다루지 않습니다. 시작하며: 왜 Kafka인가? Spaghetti Code 현대의 소프트웨어는 점점 더 복잡해지고, 비즈니스가 성장함에 따라 관여하는 이해관계자와 기능의 수도 늘어납니다. 자연스럽게
2025년 08월 27일 -
2. Kafka Producer - ACKS 옵션과 ISR, 메시지 전송 신뢰도
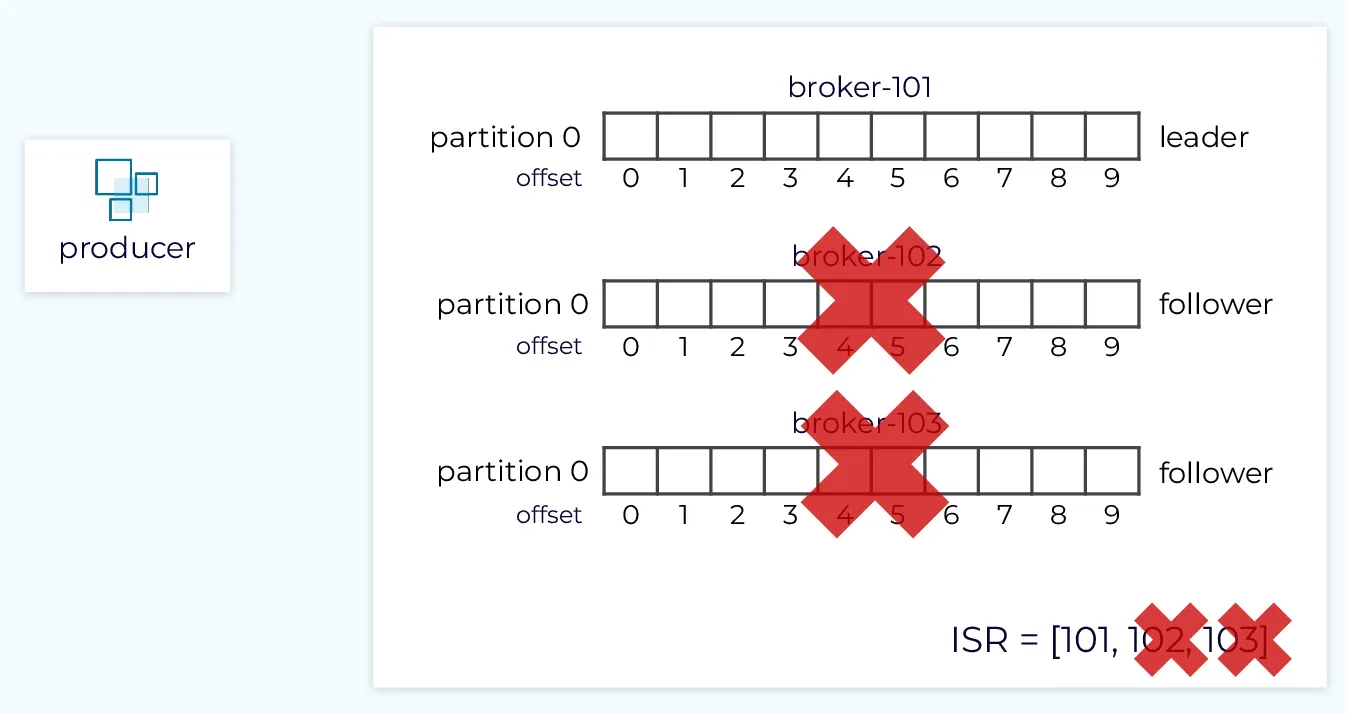
지난 글에서는 프로듀서, 컨슈머, 브로커, 토픽, 파티션 등 카프카의 핵심 개념과 아키텍처에 대해 알아보았습니다. 프로듀서가 producer.send()를 통해 메시지를 발행하면, 해당 메시지는 토픽의 파티션으로 전송되고 컨슈머가 이를 가져가 처리하는 흐름을 이해했습니다. 그런데 여기서 한 가지 중요한 질문이 생깁니다. producer.send()를 호출하고 나면, 우리는 "메시지가 안전하게 전송되었다"라고 언제 확신할 수 있을까요? 프로듀서의 요청이 리더 브로커에 도달하자마자일까요? 아니면 모든 복제본에 저장이 완료되었을 때일까
2025년 09월 02일 -
3. Kafka Consumer - 오프셋 커밋과 재처리 전략, Dead Letter Queue(DLQ)
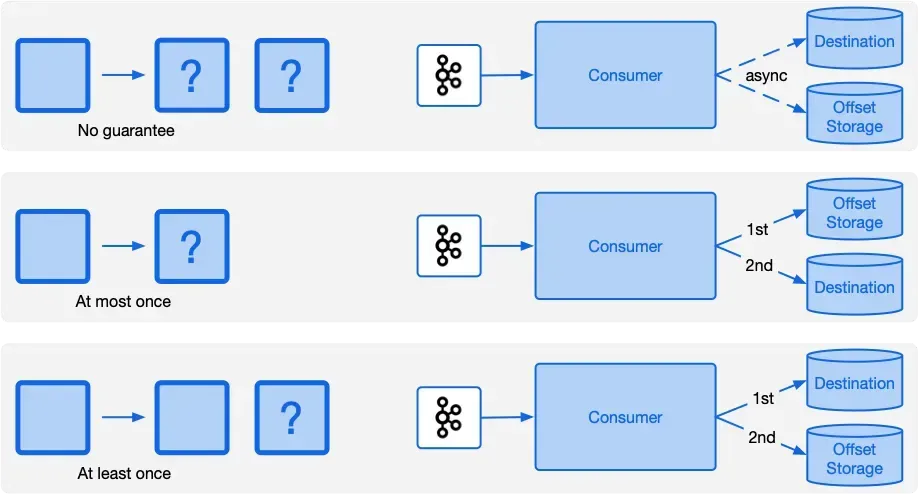
지난 글에선 카프카 프로듀서 측 주요 개념과 발생할 수 있는 시나리오 및 대응법들을 살펴봤습니다. 사실 프로듀서 측은 세팅만 잘 해두면 큰 문제가 생기지는 않습니다. 데이터의 영속화와 메시지 발행간의 무결성만 잘 지킨다면 외에는 크게 신경 쓸 부분이 없기 때문이죠. 다만 컨슈머 측엔 토픽을 다루는 서비스 로직이 들어가다 보니 발생할 수 있는 상황의 복잡도가 굉장히 높습니다. 이번 글에선 컨슈머 측에서 여러 상황을 컨트롤하기 위해 필요한 개념과 방법들에 대해 알아보겠습니다. 오프셋 커밋 전략 오프셋은 파티션 내에서 각 메시지가
2025년 09월 08일 -
4. [Spring] 카프카 의존성 - Spring Cloud Stream vs Spring Kafka
![[Spring] 카프카 의존성 - Spring Cloud Stream vs Spring Kafka](https://d2r0pavv0lsiqc.cloudfront.net/posts/images/10600609-c645-4892-8c2f-6cb15c0f1ac4.webp)
스프링에서 카프카 Producer과 Consumer를 사용하기 위해서는 대게 2가지 방법이 있습니다. 바로 Spring Cloud Stream 과 Spring Kafka입니다. 두 기술은 서로 철학과 장단이 다른데, 이름에서 볼 수 있듯 Spring Cloud Stream은 추상화 레벨이 높고, Spring Kafka는 Kafka라는 이름이 직접 들어가는 만큼 더 세밀한 카프카 지향적인 제어가 가능합니다. 이번엔 두 기술을 비교해보며 각각의 철학 및 사용법을 확인해보고 장단점을 알아보겠습니다. 스프링 클라우드 스트림 (Spri
2025년 09월 10일