protobuf & gRPC Ecosystem (2)
-
1. gRPC vs HTTP/REST - 실제 서비스 환경에서의 부하 테스트로 살펴본 성능과 오버헤드
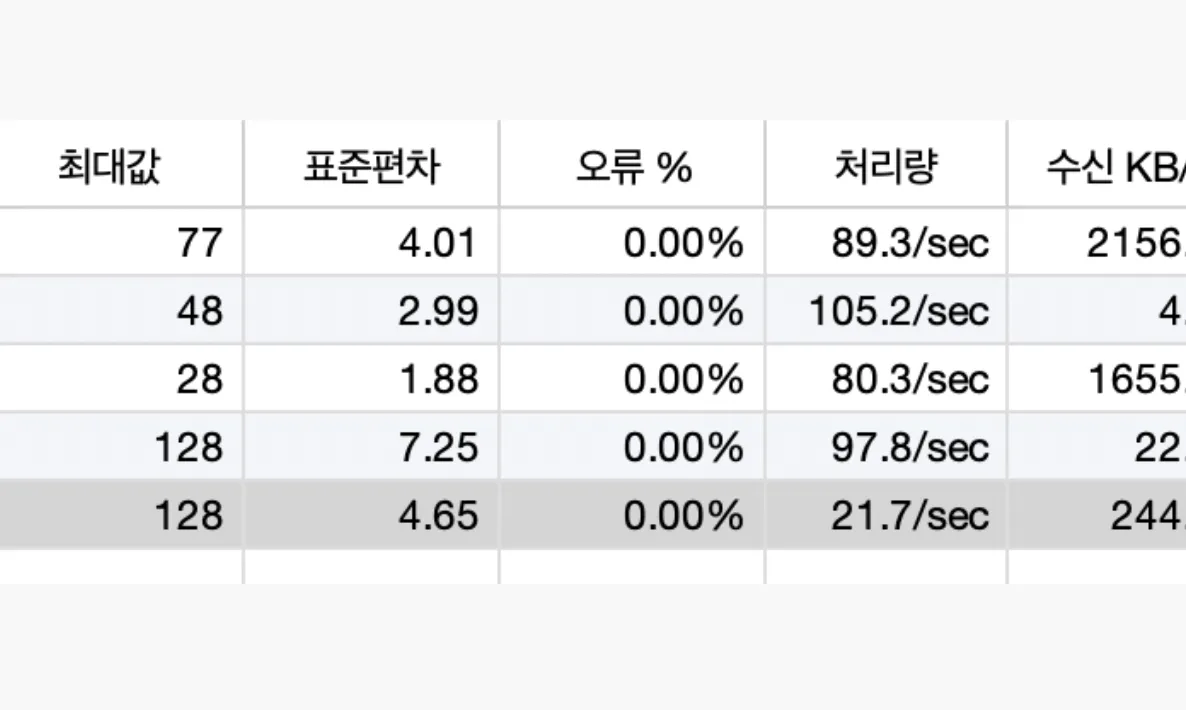
마이크로서비스 아키텍처가 자리 잡으면서 서버 간 통신 방식으로 gRPC가 주목받고 있습니다. 많은 아티클에서 “gRPC는 HTTP/1.1 기반 API보다 빠르다”라는 이야기를 접해보셨을 겁니다. 하지만 실제로 얼마나 빠른지, 어떤 상황에서 빠른지, 그리고 기존 벤치마크 결과가 얼마나 신뢰할 만한지는 직접 실험해보지 않으면 체감하기 어렵습니다. 이번 글에서는 클라우드 환경에 배포된 DB I/O, Kafka 등이 연결된 실제 애플리케이션을 대상으로 부하 테스트를 진행했습니다. 단순히 프로토콜 차원뿐만 아니라, 애플리케이션 내부의 풀
2025년 09월 11일 -
2. protobuf 관리 전략 – Submodule, Buf, Schema Registry

IDL로 protobuf를 도입했을 때 필연적으로 따라오는 것은 protobuf에 대한 관리 문제입니다. IDL은 통신에서 사용되는 공유 계약으로 이용되어 서비스가 동일한 IDL 스펙을 반드시 따라야하게 만듭니다. 특히 protobuf 같은 경우엔 각 값의 key 값이 따로 존재하지 않고 field number만 이진화되어 전송되기 때문에, 해석하는 측에서 직렬/역직렬화 과정에서 이를 올바르게 해석하려면 양쪽 서비스가 동일한 proto 정의를 공유하고 있어야 합니다. 따라 protobuf를 올바르게 사용하고 관리하기 위해서는 스
2025년 09월 14일